BookNote-大数据之路(Alibaba-OneData) Part1

成书于2017年,有些技术或许过时或者描述不再准确了,要分析地阅读。

结合我的需要,我先拆解数据模型篇和数据管理篇,然后再来看数据技术篇。
为什么,数据技术每5年一小变10年一大跳,但对于数据模型和元数据管理的理念,却还是常青。
数据模型篇
数据模型(Data Model)就是数据组织和存储方法,强调存储和使用角度合理存储数据。
良好数据模型的好处有几个方面:减少数据IO吞吐查询性能高; 减少不必要数据存储,实现结果复用;改善用户使用数据体验,提高数据使用的效率;改善数据的统计口径,提升数据质量。
关系型数据库 vs. 数据仓库
这里就不赘述了,在我的博客-对比学习(一) 第一对概念中就想到了这组。
OLAP vs. OLTP vs. HTAP
OLTP即为事务处理系统,数据库建设遵循基于范式的实体建模,在操作上主要是数据的随机读写。
OLAP面向的则是批量读写,关注的是数据整合,以及复杂大数据查询和计算的性能。
建模方法论
ER 模型 vs. 维度建模
ER模型的操作步骤:
- 高层模型,抽象模型,描述主要主题和主题间关系; 例如 充值 - 消费 - 发货 - 学习服务 - 退款
- 中层模型,在高层基础上,细分主题的数据项 —— 消费细分为订单,子订单,商品, 用户 ... ...
- 物理模型(底层模型),在中层模型基础上,考虑物理存储,基于性能和平台特点进行物理属性设计,也可能做一些合表拆表、分区设计。
Kimball维度建模
这位大师在早些年提出了 是数据仓库工程师的必读之作了。 在目前的多数公司中,都采用了(过)维度建模。
维度建模是从分析决策的需求出发,重点关注用户如何能快速完成需求分析。
维度建模步骤:
-
业务过程分析,例如前面提到的交易支付过程
-
选择粒度,这里要非常非常小心,维度和粒度的区别,在事件分析中,要能预见到分析可能用到的程度,从而决定选择的粒度。 (粒度是维度的一种组合)
-
识别维表,确定粒度后,就需要基于此粒度设计维表,包括维度属性。
-
选择事实表,确定分析需要的衡量指标。
其它模型
Data Vault模型,了解不多。
Anchor模型 对Data Vault模型做了进一步的范式处理,将模型规范到6NF。
阿里巴巴数据建模实践
阶段一 Oracle(ODS层)+DSS层
基本没有系统化的建模体系。
阶段二 引入MPP(Greenplum)
用ER模型+维度模型,四层架构。
ODL(操作数据层)+BDL(基础数据层)+IDL(接口数据层)+ADL(应用数据层)
第一层 ODL 贴源层,和源系统保持一致;
第二层 BDL,引入ER模型
第三层 IDL,基于维度模型构建集市层
第四层,完成应用的个性化和基于展现需要的数据组装
经验: 在快速变化的业务阶段,构建ER模型风险大
阶段三:Hadoop时代,以Kimball维度建模为核心,加以升级和扩展
数据公共层建设,解决数据存储和计算的共享问题。
“OneData” , 需要长期的数据整体设计。
OneData 数据整合方法论
定位价值: 建设统一规范的数据接入层(ODS)和数据中间层(DWD和DWS),通过数据服务和数据产品,完成公司的大数据系统建设,即数据公共层建设。
(注,这里不会涉及到主题和个性化业务)
能提供标准化的,可共享的数据服务能力,降低数据互通成本。
😌
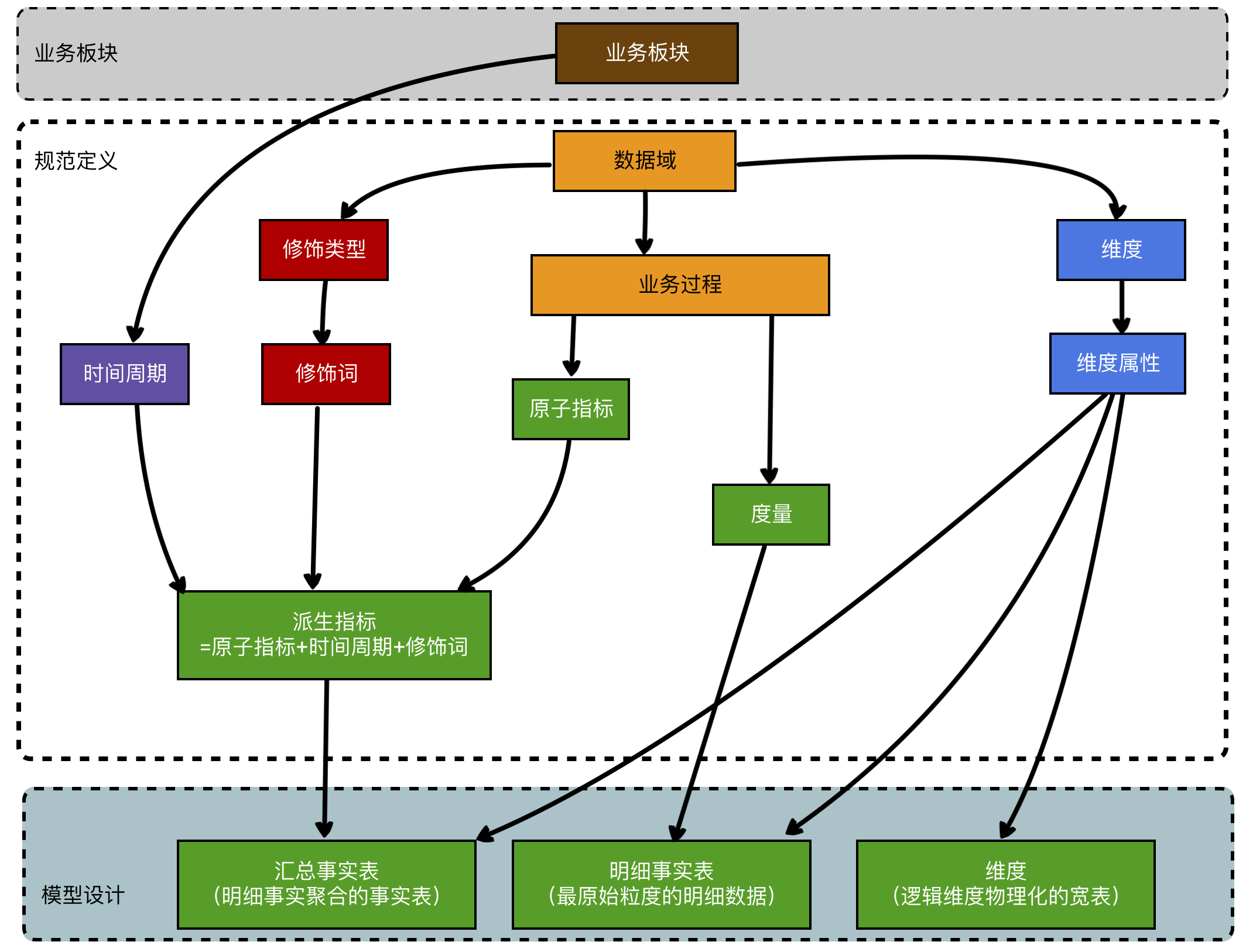
解释:
- 数据域:面向业务分析,将业务过程或者维度进行担负的集合。 数据域要长期维度和更新,但变动频率不高。
- 业务过程,指不可拆分的行为事件,在之下可以定义指标,比如销售流水额。
- 时间周期,明确统计时间范围或时间点的时间描述,如最近xx天,自然周,自然月,截止昨日,截止当日。
- 修饰类型,对修饰词的抽象划分。 修饰类型从属于业务域,如日志的访问终端类型。
- 修饰词,修饰词隶属于一种修饰类型,在「日志访问终端类型」下,分为修饰词PC端,无线端。
- 度量/原子指标,原子指标即为度量,基于业务事件行为下的度量,是业务定义中不可再拆分的指标,比如销售流水额。
- 维度是指度量的环境,如下单事件,用户买家是维度,商家平台也是维度。 维度属于一个数据域,如地理维度,时间维度。
- 维度属性是隶属于一个维度,比如地理维度中的国家,省份和城市。时间维度中的年季月周日。
- 派生指标,派生指标是数据产品中真正被使用的指标,它由原子指标+若干个修饰词(可没有)+时间周期。 比如原子指标-销售流水额,对业务来说要看的是xxx业务线最近30天新注册用户发生的流水额
- 销售流水额,原子指标
- 最近30天是时间周期
- 新注册是修饰词
- 用户买家是维度
如果有一棵指标树,原子指标是所有指标树的
派生指标可以选择一个或多个修饰词,也可以不指定修饰词。 例如时间修饰+业务粒度修饰+用户类型修饰——4月虚拟课程业务线首次付费用户数。
修饰词如果指定多个,它们之间的关系还可以进行逻辑运算:且运算、或运算。
派生指标的种类
- 事务型指标:对业务活动进行衡量的指标,新增注册用户数,订单支付金额,在此基础上创建派生指标。
- 存量型指标:对实体对象某些状态的统计,商品总数,注册用户总数,对应时间周期一般为“历史截止某时间”。
- 复合型指标:事务型指标和存量指标基础上复合计算出来的指标,例如浏览商品页面UV-下单用户数转化率
复合指标的规则:
- 比率型:创建原子指标,如CTR
- 比例型:创建原子指标,如最近7天某业务线支付金额占比
- 变化量型:不创建原子指标,增加修饰词。
- 变化率型:创建原子指标,例如最近7天新注册用户支付金额7天周比变化率,原子指标是支付金额变化率,修饰类型是买家类型,修饰词是新注册用户
- 统计型:不创建原子指标,增加修饰词,如均值,分位数,人均,日均,行业平均
- 排名型:创建原子指标,
指标命名规范
每个公司的数据团队都应有规范的数据库、数据表、字段的命名规范。
这也是数据治理和质量的一部分,切忌百花齐放。
时间周期修饰词
最近x天: 用 xd 来描述,如 最近1天 - 1d,最近3天 - 3d
7的倍数,最近7天:1w,最近14天 - 2w
30的倍数,最近30天: 1m,最近60天-2m,最近90天-3m
自然周: cw
自然月: cm
自然季: cq
年初至当日:td
零点截止当前:tt
财年:fy (financial year)
准实时: ts
未来7天:f1w
未来4周: f4w
模型设计
阿里巴巴数据公共层设计理念遵循维度建模思想,参考 Star Schema-The Complete Reference 和 The Data Warehouse Toolkit-The Definitive Guide to Dimensional Modeling.
数据模型的维度设计主要以维度建模理论为基础,基于维度数据模型总线架构,构建一致性的维度和事实。
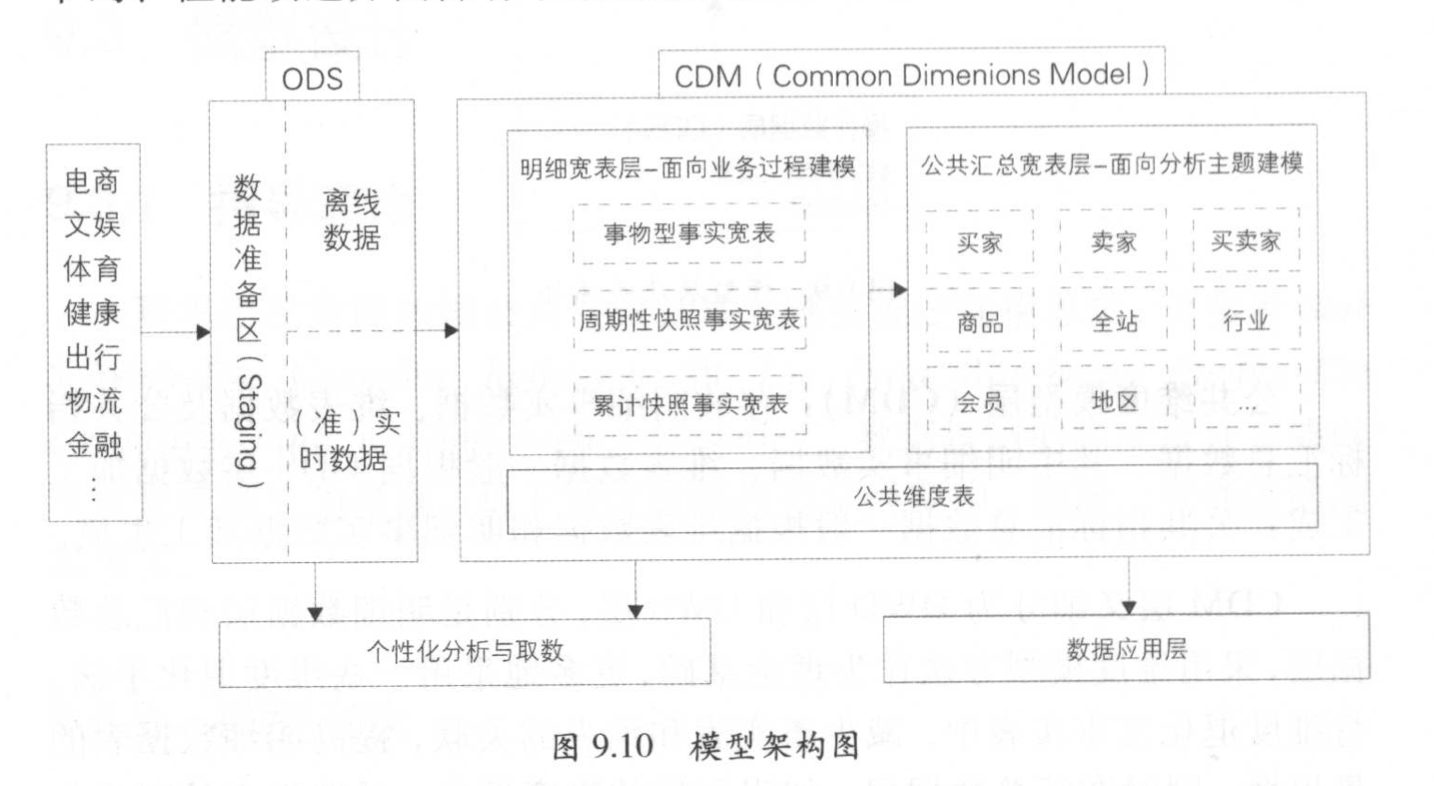
模型层次:
- 操作数据层,ODS 上游数据几乎无处理的存放在数据仓库,完成以下数据任务:
- 数据同步,增量和全量同步到集群;
- 结构化,非结构化(一般为日志)结构化处理和解析存储;
- 累积历史和清洗,按业务需求和审计要求进行历史数据的归档和清洗。
- 公共维度模型层,CDM,存放明细事实数据、维度数据及公共指标汇总数据
- 设计思路1:维度退化,将维度表退化至事实表,减少重复关联,提高明细数据表的易用性
- 在汇总数据层,加强指标的维度退化,采取更多的宽表手段构建CDM
- 应用数据层,ADS,存放数据产品个性化的统计指标数据,由ODS和CDM层加工而成
- 个性指标:不通用(几乎是case by case), 复杂性(指数型,比值型,排名与统计型)
- 基于应用的数据组装:大宽表集市,横表转纵表,趋势指标串。
模型设计的基本原则
- 高内聚,低耦合:业务相近的、粒度相同的设计为一个物理或逻辑模型,低概念同时访问的数据分开存储;
- 核心模型与扩展模型,核心模型支持常规的数据服务, 扩展模型支持个性化或少量应用,难点——控制扩展模型对核心模型的入侵
- 公共处理逻辑正常,公共处理逻辑不宜暴露给应用层实现
- 成本 vs. 性能 适当数据冗余可换来查询的性能提升
- 数据处理幂等性,处理逻辑不变,不同时间多次运行数据结果确定不变
- 命名规范,相同含义字段在不同表中命名必须相同,命名清晰、易于理解
数据模型开发与设计的日常工作流
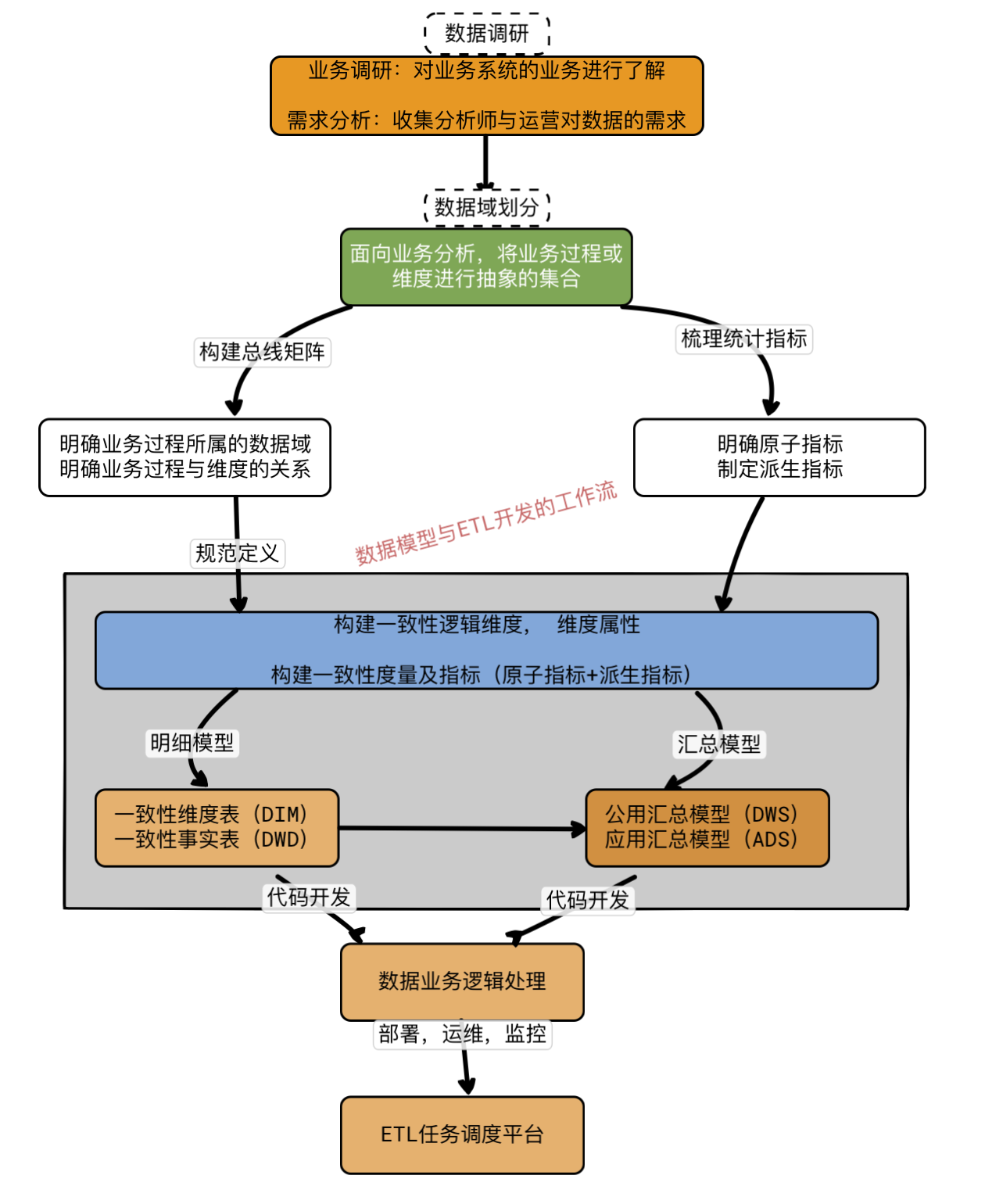
需求调研是起点,一般由数据产品和数据仓库工程师面向分析师和运营配合完成。
总线架构设计
数据域是面向业务的,将一个核心业务动作汇聚成一个数据集合。

总线矩阵:
明确数据域下面有哪些业务过程;
明确业务过程的context,即维度描述。
举例:
- 采购-分销域
- 业务过程(采购,发货,入库)
- 一致性维度:供应商,业务类型,地区,仓库,类目,采购单,发货单,入库单
规范定义与模型设计
对指标体系的定义,包括原子指标、修饰词,统计时间周期,从而推理派生指标。
模型设计包括维度定义,属性的定义,以及维度表、明细事实表和汇总事实表设计。