对比学习--Big Data(一)
💚
数据仓库 vs (关系型)数据库

关系型数据库, 面向事务 OLTP
数据库, 信息的持久化,提供了库表字段设计的规范和约束,同时有索引机制,大大加速了查询的性能。
解决的是事务操作,当业务发生时,需要把这一业务事件永久的记录下来,以便后续调用查验信息。
(数据库前身, 本地结构化文件)
- 定位:数据库聚焦存储本业务关心的数据
- 建设:业务过程中产生的实体表,动作表
- 数据范围: 面向Application 或Service
- 数据类型: 主要是明细数据
- 设计: 尊重数据库设计的范式规范, 表和表的关系使用外键连接。
- 计算场景:复杂查询较少。 通常是判断一条数据是否存在, 更新或插入一条数据的值
从关系型数据到数据仓库演变 MPP? Greenplum(基于PostgreSQL)
传统数仓之外的补充,纯为OLAP解决。
数据仓库,面向分析 OLAP
- 定位: 满足公司级全面分析和数据计算的需求
- 建设: 面向主题subject的。
- 放什么范围的数据: 业务分析需要, 会集成所有数据库的数据; 同时包括关系数据库之外的信息, 日志采集系统,爬虫系统,离线上传数据, etc
- 放什么类型的数据: 既包括明细数据,也包括汇总型数据,
- 设计:用空间换时间的思想。 反范式
- 计算场景:查询复杂,多表关联是必要过程, 借助大数据
- 存储: 使用Hadoop分布式
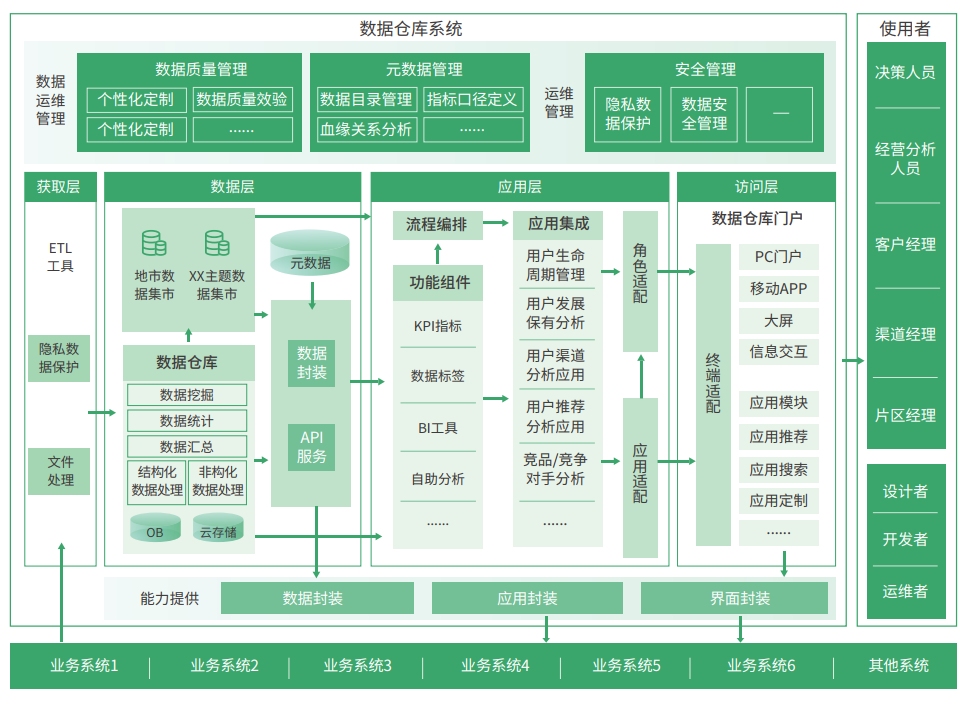
Hadoop vs. Spark
关键点:
- Hadoop的Shuffle必须要写到磁盘, vs Spark 的Shuffle(不一定落盘,cache到内存);
- 编程API,MapReduce提供的是Low API, Spark拥有RDD和DataFrame的灵活算子。
- JVM优化, Hadoop MR 启动一个Task就会启动一次JVM,基于进程的操作。 Spark每次MR操作是基于线程,启动Executor时启动一次JVM
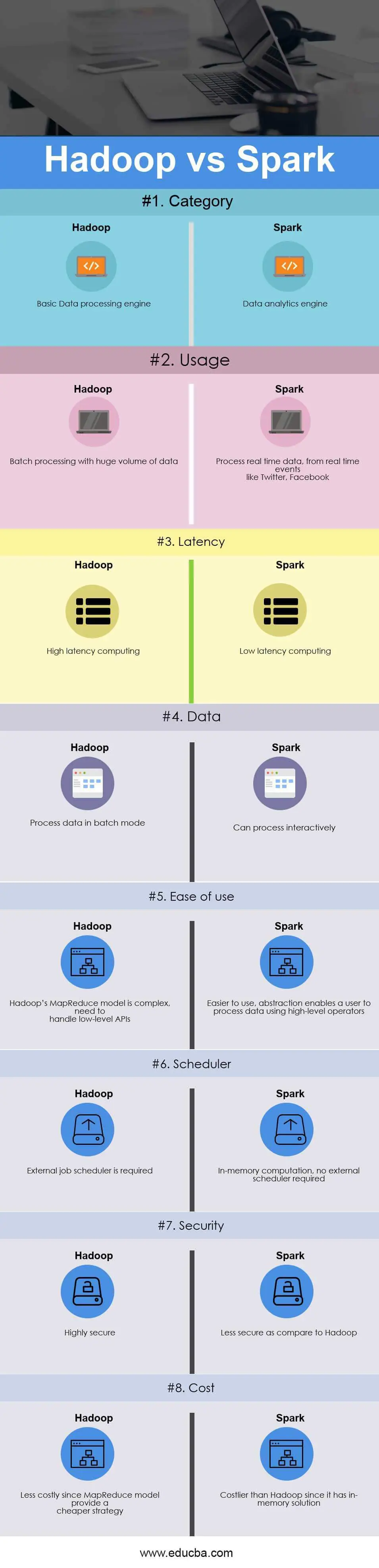
定位
Hadoop 由 HDFS, Common,YARN和MapReduce 几个模块组成, 开源的大数据处理和分析框架。
HDFS负责存储, YARN是资源管理和调度,MapReduce负责具体的计算和数据处理。
Spark是计算引擎,无存储。 由Spark Core, Spark SQL, Spark Streaming, Spark MLib, Spark Graphx组成。
Hadoop解决的是批计算任务,适合于一定延迟但数据量巨大的任务;
Spark则是批处理,相对来说数据任务的Dataset要少一些。
同时Spark Streaming能处理微批计算,能解决伪实时的分析需求。
性能差异 MapReduce执行过程中会有频繁的磁盘传输,Sprak把中间结果存储在内存中,减少磁盘IO,所以性能上要比MR提升明显。
编程模型 MR任务经历了几个阶段的开发模型。
传统MR任务是使用Java开发Mapper, Reducer任务。
后来用Hadoop Streaming,可以用Shell Python 等脚本实现MR, 之后Hive 引入了SQL,可以让用户用SQL的方式完成MR任务。 大大降低了MR任务的开发门槛。
Spark 提供了RDD和DataFrame,内嵌了丰富的算子。
语言支持 Hadoop Java, Spark是Scala, 但也支持Java。 Spark提供了Python R的扩展。
解释RDD的弹性:
存储弹性,内存和磁盘的切换; (RDD封装的是计算逻辑, 并不保存数据)
容错: 数据丢失可自动恢复; 分片弹性,可根据需要重新分片; 计算弹性:计算出错的重试机制。
Kafka vs. Flume
Kafka为什么快?
DMAC + Zero Copy
常规的实现,读磁盘中的文件,将之加到内存,再通过Socket把它发到网络中。
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
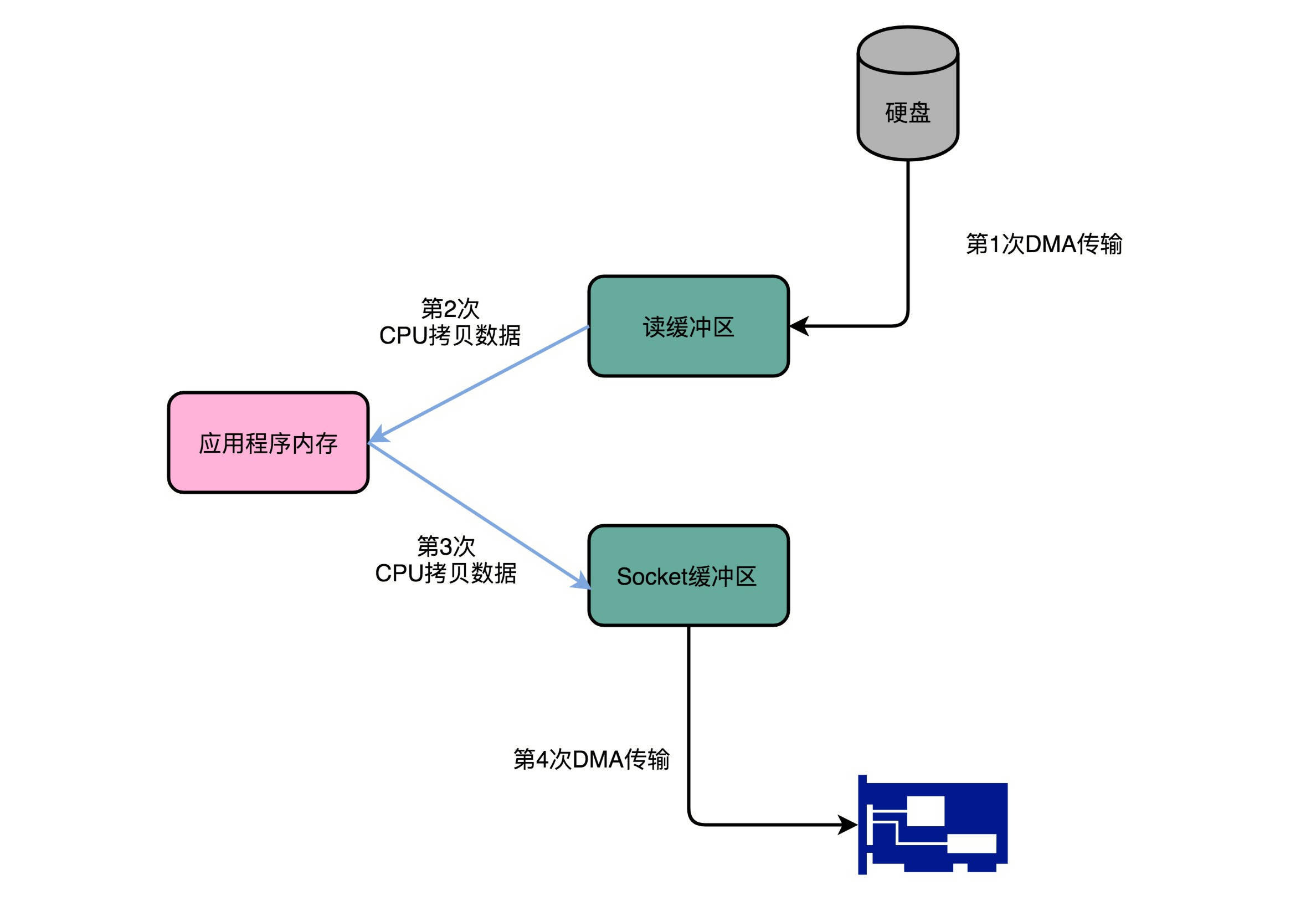
四次传输:
- DMA实现: 从硬盘,把文件读到内核缓冲区;
- CPU搬运:从内核缓冲区,复制到分配的内存;
- CPU搬运:从内存,写到Socket缓冲区;
- DMA搬运:从Socket缓冲区,写到网卡缓冲区。
Kafka 干得就是数据搬运的工作,自然要在这个流水线下了大力气优化。 优化后的成果,是将上面的四次搬运缩减为两次 —— 只有首尾的第一次和第四次,跳过了CPU工序。 因为跳过了中间的复制数据环节,所以这个过程也称为 “零拷贝”(Zero copy)
// 调用 Java NIO 的 transferTo 方法
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
Kafka: broker 组成的Kafka集群作为服务者,处理生产者(Producer)和消费者组(Consumer Group)的发送消息和消费消息