大数据生态
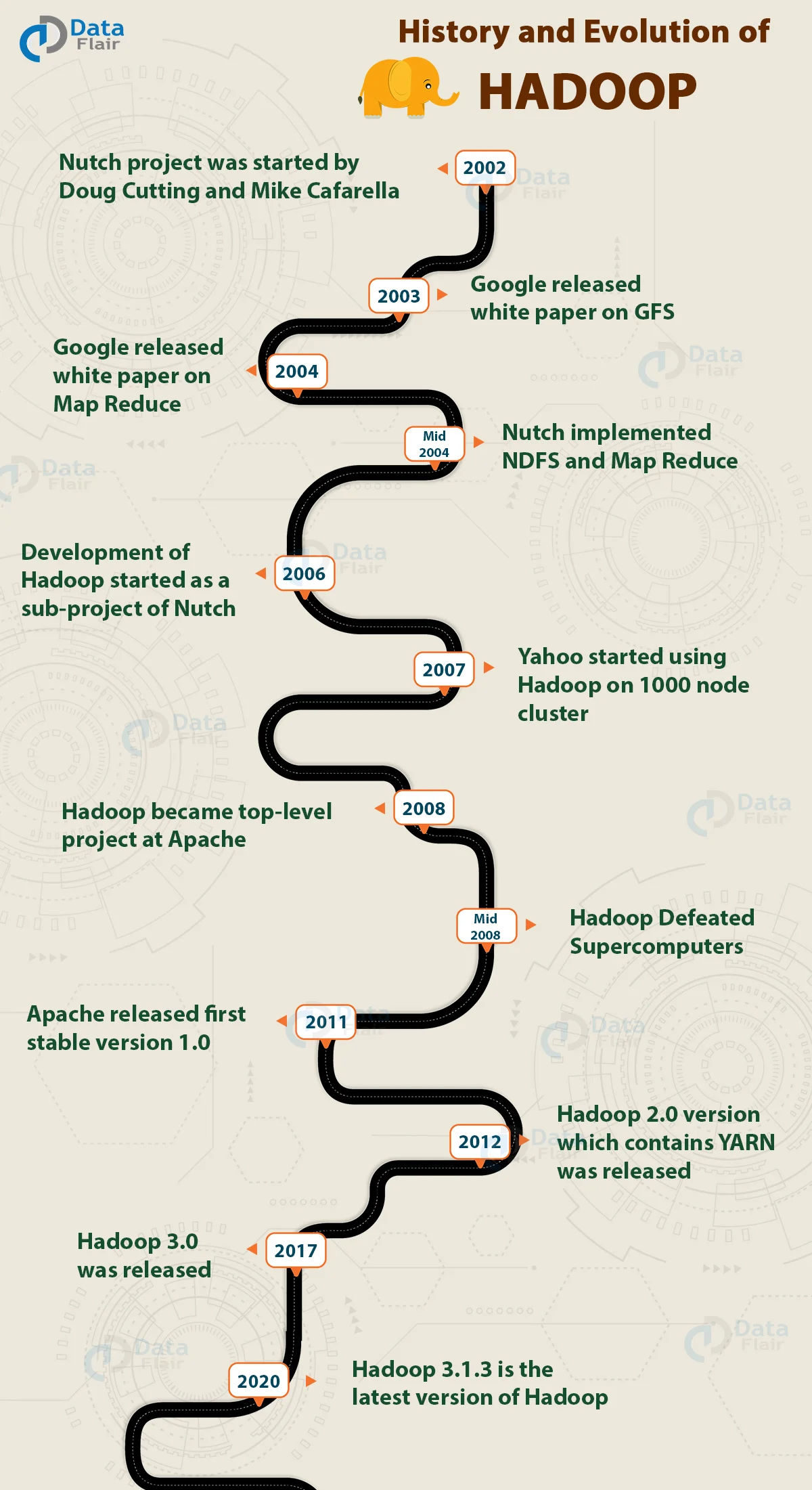
Hadoop Evolution
- 2002 Nutch project
- 2003 - 2004 Google Paper (GFS, MapReduce)
- 2008 Hadoop ——Apache Foundation , top-level project
- 2011, Hadoop1.0 released
- 2012, Hadoop2.0 released + YARN
- 2017, Hadoop3.0 released (Java , MR Optimization)
- 2020, Hadoop3.1.3
MapReduce是21世纪计算机科学个有里程碑意义的技术革新,将“分治处理”应用到了大型数据处理领域。
- 网页爬取
- 日志处理
- ... ...
恰好它诞生在web2.0 爆发的时期的互联网广告领域,进而影响了后面的移动互联网。
同时,MR的使用前提也需要新的文件系统。
HDFS
HDFS是主从架构, 主为NameNode,从为一些DataNode,主存储了集群的数据元信息,帮助应用程序锁定位置,从是负责存储和计算的节点,并通过心跳和主节点汇报自己的健康状态和block信息。
一般集群的建议是DataNode数量小于5K。
SNN,Secondary NameNode
周期性的完成对NameNode的Editslog和FsImage的合并,减少Editslog大小。
Block(数据块)的放置策略
- 第一个副本放在上传文件的所在DataNode
- 第二个副本放在另一个rack上的节点
- 第三个副本放在与2号副本相同rack的另一台节点上
- 第四个副本: 随机。
Hadoop MR计算框架的一丿 —— WordCount
// Mapper
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final statck IntWritable one = new IntWritable(1);
private Text word = new Text();
public void Map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
// Reducer
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWriterable> {
private IntWritable result = new IntWritable();
public void Reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val: values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
// Job entry
public static void main(String[] args)throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.addOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
计算如何向数据移动?
在MR计算框架中,有几个角色:
- 客户端应用, 任务清单(Split切片信息)
- split 和block 的对应关系 由NameNode存储映射
- 客户端要把自己的计算逻辑移动到存有block的DataNode上, 客户端任务有一个统筹管理者 —— ApplicationMaster
- JobTracker(资源管理+任务调度
- TaskTracker(任务管理 资源汇报)
计算逻辑由客户端上传到HDFS, 副本数大于3;
Spark
随着Hadoop的推广和普及,MR的性能问题也成为了诟病的地方。 MR 的问题:
-
操作算子单一,只有Map 和Reduce两种,开始繁琐,特别是对于多表Join;
-
Shuffle(Map与Reduce的中间过程)必须要落盘,磁盘开销大,严重影响任务的性能;
-
LowAPI, MR 在Hive提出之前,开发门槛很高; Spark提供了Python (PySpark),Spark SQL, 以及 Spark MLlib, 对于开发和应用上,非常友好。
Spark提供了丰富的操作算子: filter, join, flatMap, union 等。
逻辑上将代码分为逻辑处理层和物理执行层,逻辑上将应用解析成一个DAG(有向无环图),定义数据及数据间的操作关系。
每个action 定义一个job。
每次shuffle过程会创建一个新的Stage。
Spark的Shuffle
Spark 的WordCount
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount").setMaster("local[*]"))
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val count = spark.read.textFile("input.txt")
.flatMap(_.split(" "))
.Map(s => (s, 1))
.rdd
.ReduceByKey((a, b) => a + b)
.collect()
}
}