Data warehouse - Design
数据仓库 vs 数据库, 阅读我的另一篇文章
Data Warehouse 是给谁设计的, 正如Service Engineer, 他们建设的Application/Server是服务于公司的客户。 而DataWarehouse是给公司的决策层和分析层使用的, 所以面临的挑战是:
- where can I find the proper data I want 我怎么能够便捷的找到我想要的数据。
- How good is that data? 这个数据的呈现形式是我想要的吗, 是否易用?
- How can I get access to that data ? 这个数据我是否能访问, 怎么访问?
Gartner 曾做过一次调查,对企业内部发现进行业务决策面临的数据挑战来自于no data, poor data, complex data。
no data 压根没有数据;
poor data, 数据不完全;
complex data, 数据需要额外的加工和解析,无法直接成为决策依据。
Data warehouse 的联想:
- 数据组织成本高, 需要有专人维护
- 存储数据量大
- 计算任务多且种类繁杂
- 数据用度广泛
数据仓库, 公司的业务决策系统,不直接面向用户提供服务.
(decision support system)
数据仓库是围绕特定业务主题的产物.
公司的业务可以细分, 不同业务系统在数仓中用"主题" (subject)进行逻辑上的划分.
数仓建设的方法论
Inmon范式建模
根据3NF自上而下建模,将数据抽取为实体和关系模型, 不强调事实表和维度表.
根据上游数据生产,加工成数据仓库,再产生数据集市关心的指标.
数据源往往是异构的,强调数据清洗工作.
Kimball维度建模
自下而上建模,从数据集市->数据仓库->数据源,以最终任务为导向,将数据按照目标拆分为不同的需求.
数据会抽取为事实-维度模型.
数据源经ETL转化为事实表和维度表,导入到数据集市, 数据集市是数据仓库中的一个逻辑上的主题域.
data vault modeling
Data Vault(保险箱?)是 Dan Listedt提出,面向细节,可追踪历史。
由中心表,链接表和附属表三部分,核心是中心表,存储业务主键,链接表存储业务关系,附属表存储业务描述。 英文文章中用 Hub,Link和Satellites表示。
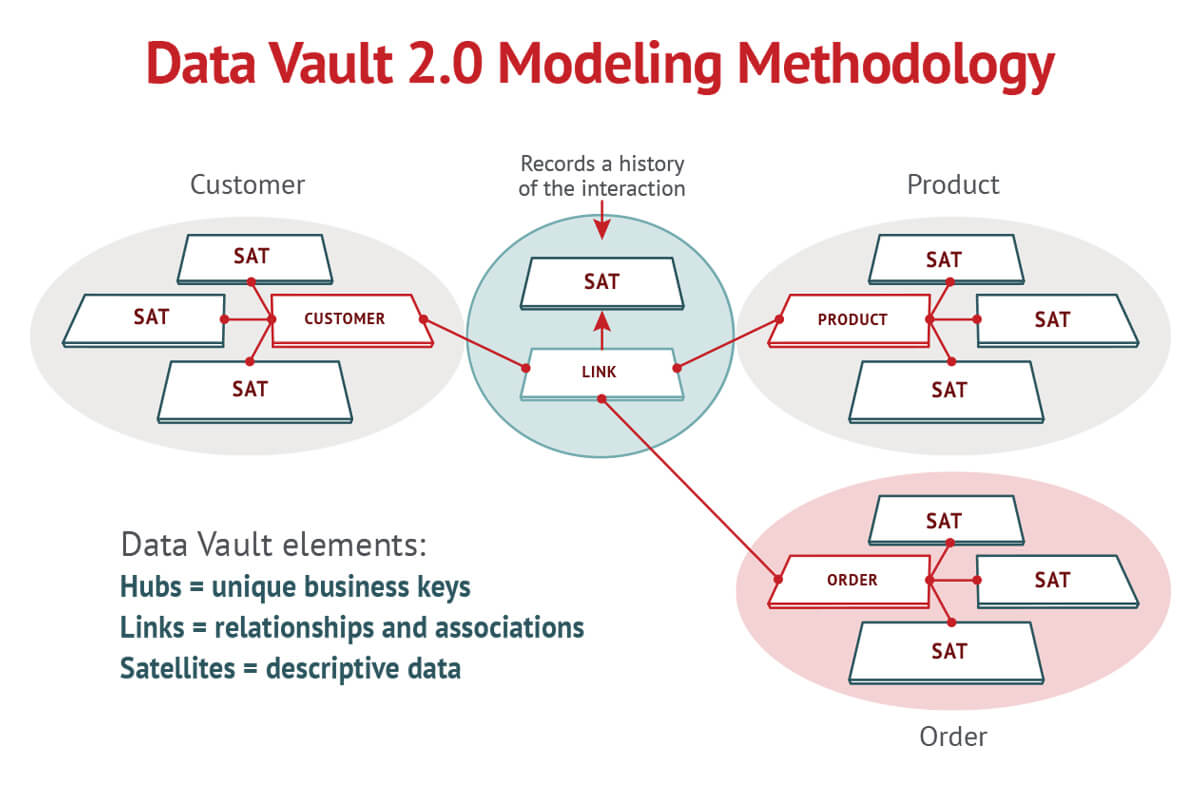
几种建模实践


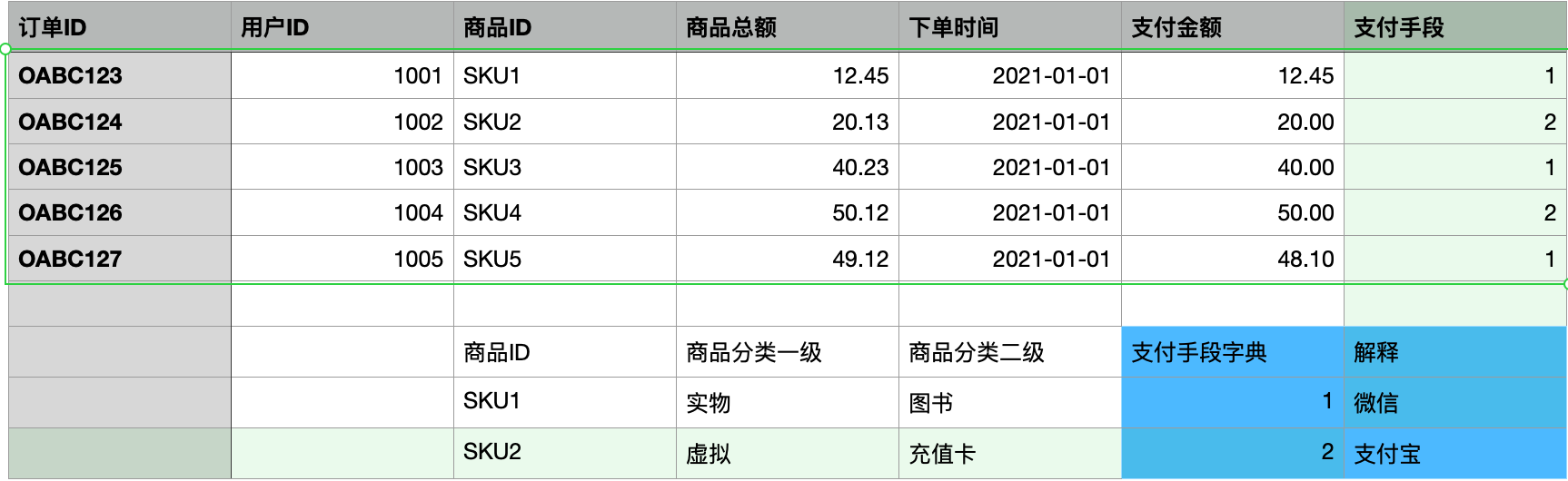
如果遵循Inmon执行范式建模,要准备若干个表:
- 城市信息实体表
- 订单与用户的关联表
- 支付手段解释表
- 商品信息分类表
- 用户注销状态解释表
- ... ...
即 实体是实体, 两个实体之间的relation 表. 这是ER设计的理念,也是 Inmon的模式.
Kimball模式建模
Kimball关心业务的核心过程,在这里只有一个业务过程,即用户下单. 所以事实表只有一个: 订单事实表
用户表在这里是一张特殊信息维度 ---- 虽然用户的注册,资料更新也是用户的操作,但对于业务来说,并不是商业动作,而是产生动作的来源,和"商品"等价.
城市表,支付方式表,商品分类表,都是与支付有关的维度表.
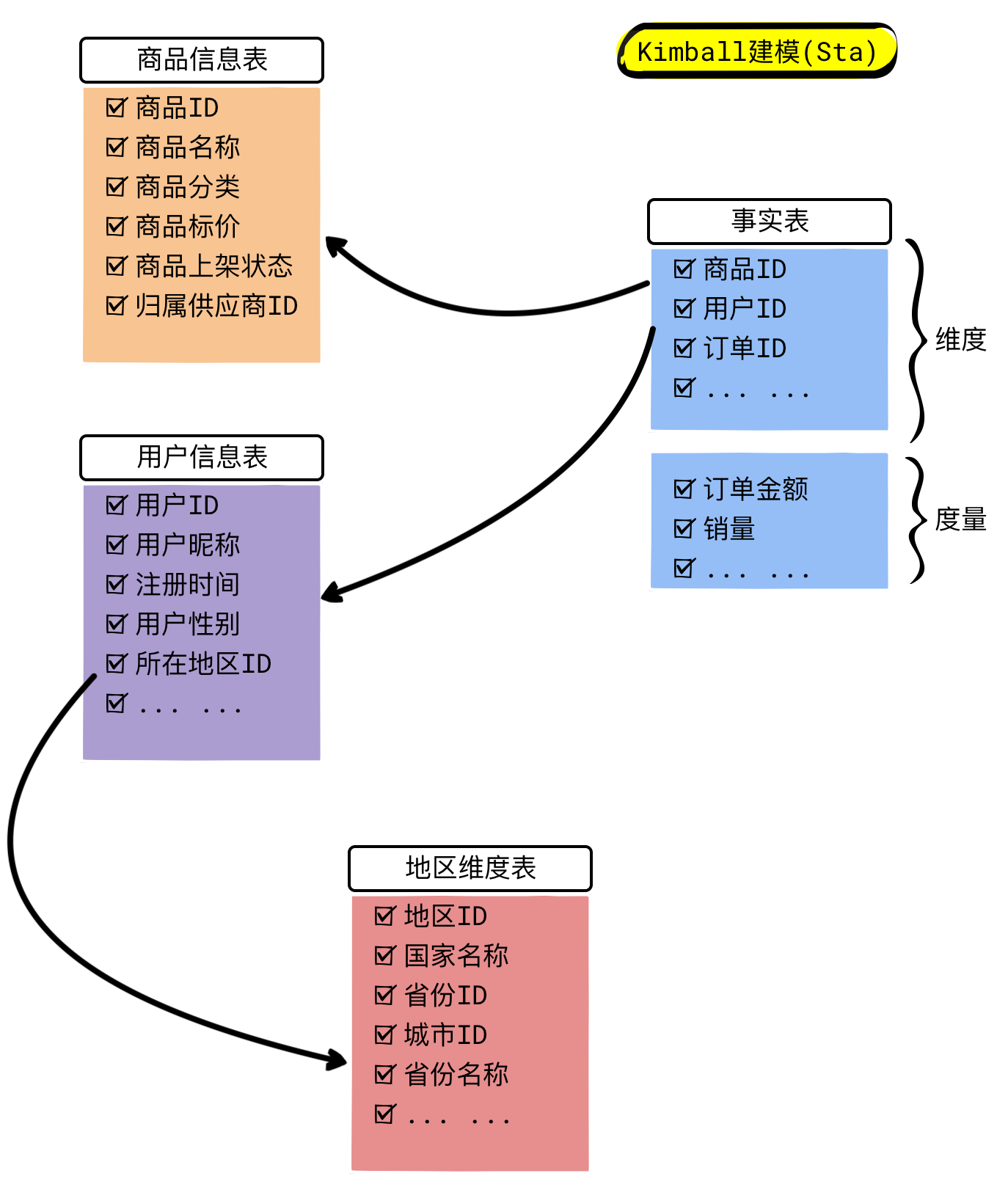
上图,维度建模的示例,雪花模型
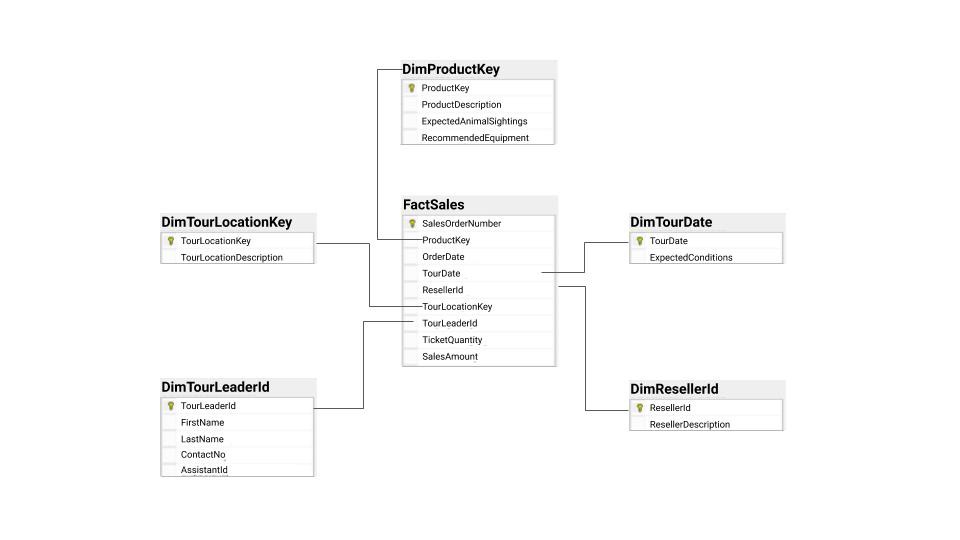
上图,维度建模的示例,星形模型
图片来自 towardsdatascience
分层设计-物理分层
Data Staging Area 是OLTP-上游关系型数据库进入数仓之前的缓冲层,可以进行简单的数据清理操作.
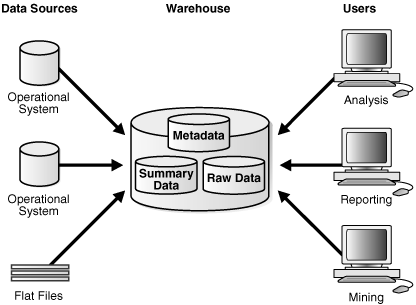
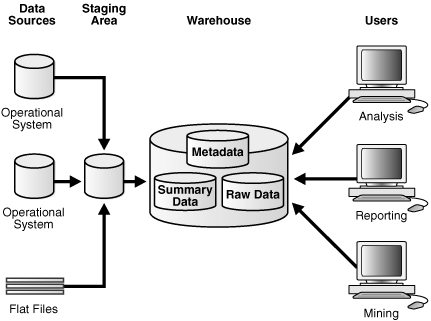
ODS 层是做什么?
分主题设计,构建总线矩阵
主题域是业务过程的抽象集合。
业务过程就是公司经营过程中一个个不可拆分的行为事件,但并不一个业务过程就单独划分一个域,而会进行一些合并,如下面的流量域:
商品域: 业务过程商品的创建和上架下架,是交易的基础依赖域;
用户域:用户有关的数据,包括注册,登录,用户身份管理;
供应链域:商品内部采购和调拨业务过程;
物流域:商品配送的物流快递数据;
仓储域:仓库存储相关的数据,入库,出库;
流量域:一般是电商平台用户相关行为数据,搜索、曝光
交易域:加入购物车、下单、支付,与用户购买直接相关的过程;
售后域:电商平台交易的逆过程,包括工单申请、退货订单;
促销域:商品促销有关的数据,包括优惠券、抢杀、拼团等;
内容域:内容社区,包括发布、分享等业务过程;
... ...
主题域划分的要求:
稳定性——相对稳定,新加入一个主题域,不影响已划分的主题域;
扩展性——有一定的扩展性,允许某些主题域凋零下线;
总线矩阵: 主题域 + 业务过程 + 可分析维度
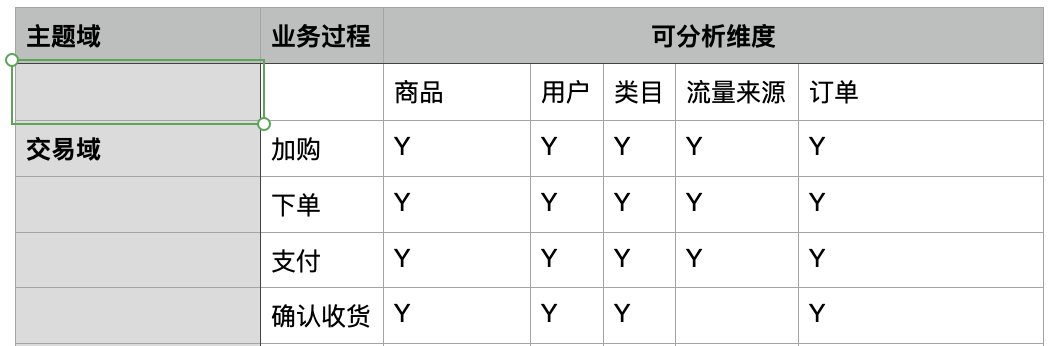
构建一致性维度。
数仓设计难题 - 不同主题的边界如何划定
Cube vs. Granularity
(维度 vs. 粒度)
设计技巧 -- 数据模型设计,怎样提升复用?
先了解集群
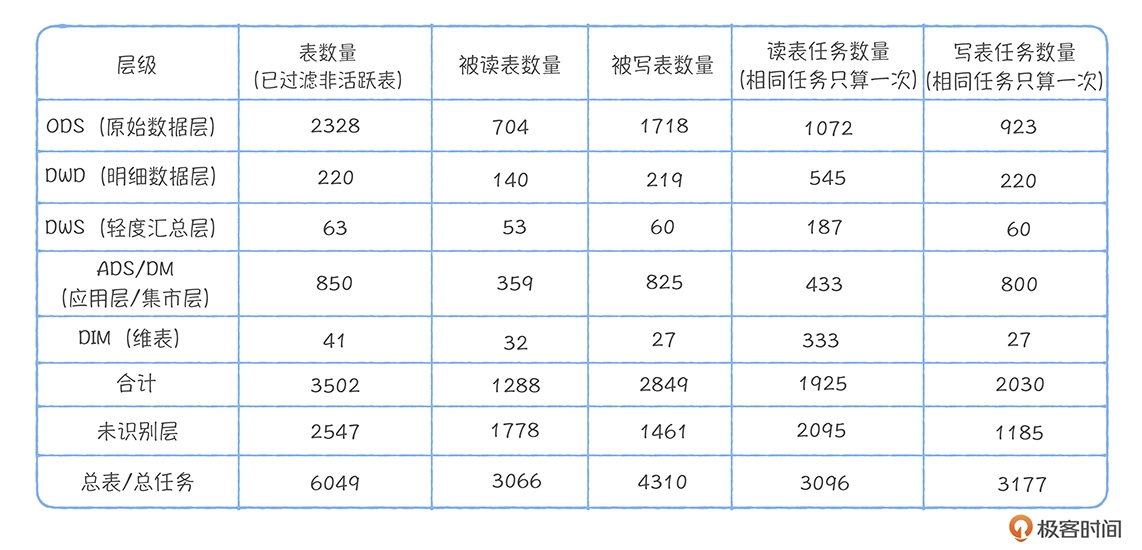
使用率: 在一定时间范围内,对每层的所有数仓表计算它们有多少被查询任务命中🎯;
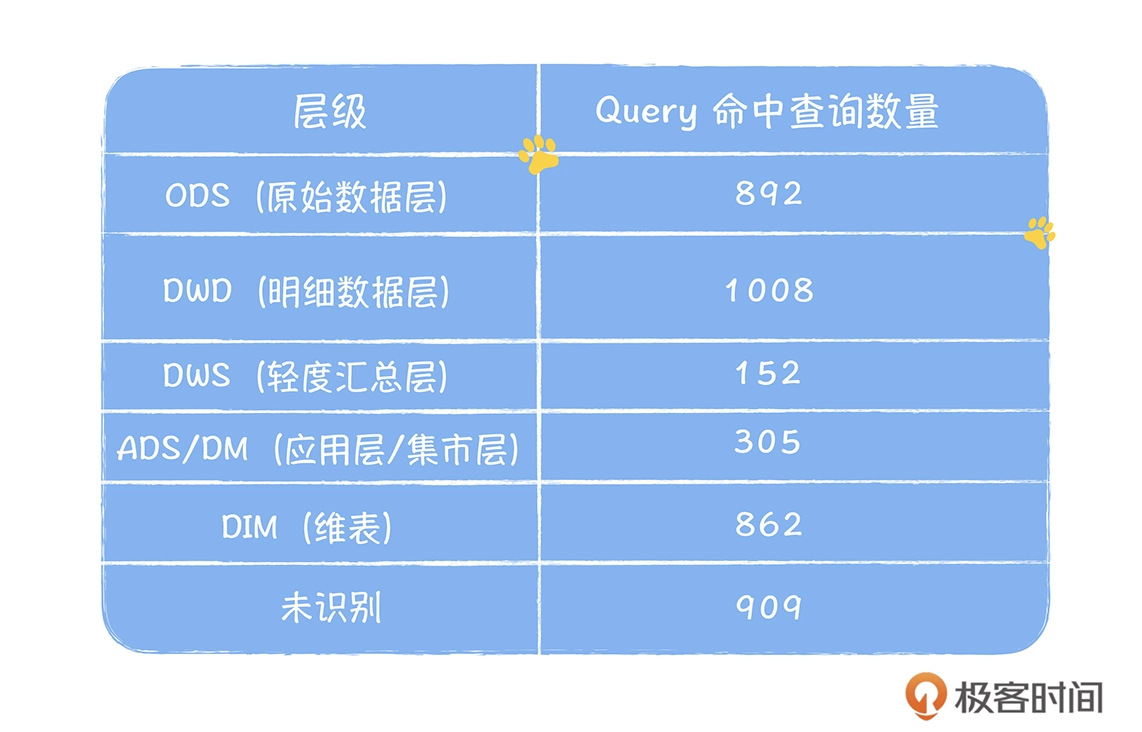
ODS(原始数据层):892;
DWD(明细数据层):1008;
DWS(轻度汇总层):152
ADS/DM(应用层,集市层):305
DIM(维度表):862
衡量DWD层是否完善,一般看ODS层有多少被上层引用。 ODS层跨层用得占比过高,说明DWD建设度不成熟。
之前我在的公司是把所有ODS层都执行了DWD层的复制,再定期计算DWD层的跨层引用率,即由DWD层有多少比例的表被DIM、DM、ADS层有效依赖。
(无效依赖是指,有些任务曾经依赖过,但任务已经下线)
DWS/ADS、DM层的完善度:考核汇总层和应用层的完善程度,则主要看满足查询需求的程度。
即在查询需求中有哪些是对这三层的表的零依赖。如果这样的任务太多,说明这三层建设要进一步提升。
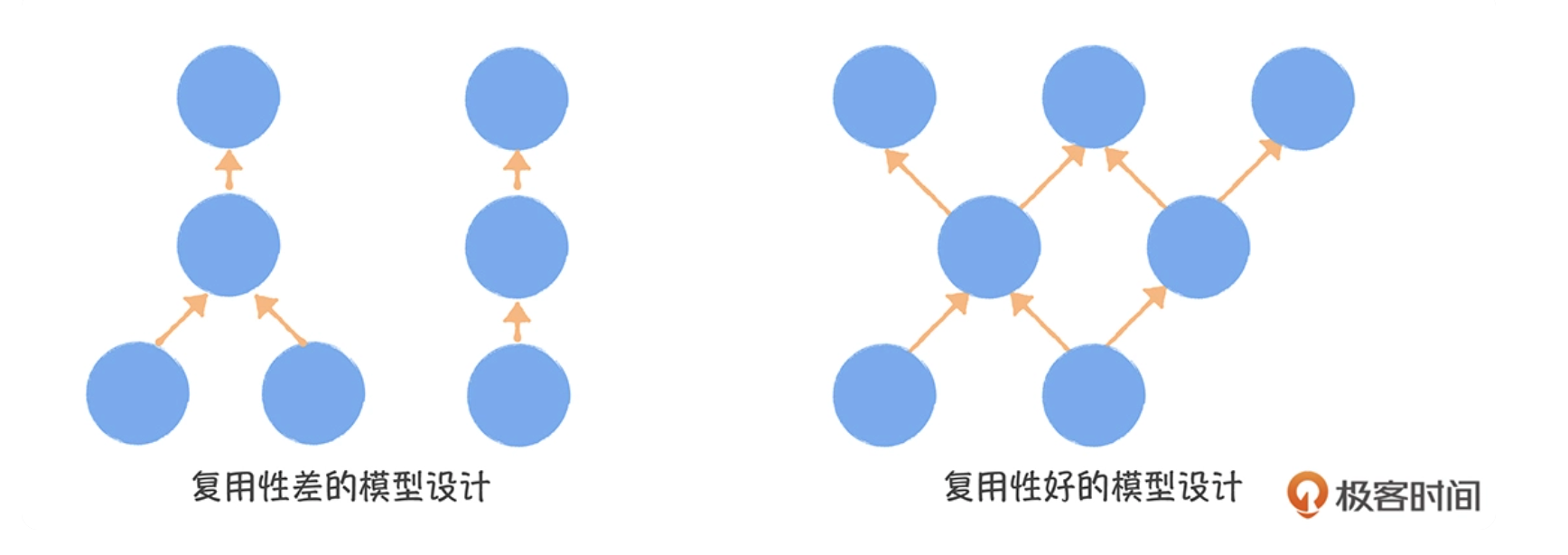
(图片来自 《数据中台实战课 - 极客时间)
Zipper Table 拉链表
即累积历史全量表,记录了某一实体从产生到当前的全量统计信息, 通常为用户创建的居多, 一行表示一位用户的累积统计信息: 以user_id 为唯一主键
- 用户注册日期, 联系方式等静态信息
- 用户首次付费日期, 用 9999-12-31 这种无效数字表示还未发生的数字,而不用NULL值
- 用户累积付费金额,
- 用户的xxx
- (关键) 统计窗口的起始日期
使用场景, 基于历史快照的统计, 比如2019年12月31日,系统累积有付费用户数是多少?
拉链表几乎是要每天更新的,动态更新这个窗口.
拉链表的开发和实现比较容易,要遵循历史+增量的merge逻辑.
可进一步参考这篇文章