对比学习--Big Data(二)数据倾斜
什么是数据倾斜(Data Skewing)
数据倾斜的前提是分布处理,本质是Shuffle过程时不同Reducer节点的处理处理不均衡;
现象是在观看各Task运行耗时,发现绝大多数Task在很多时间内完成了,而只有部分任务一直在运行,典型数字是一直卡在了99%。
倾斜的常见场景:
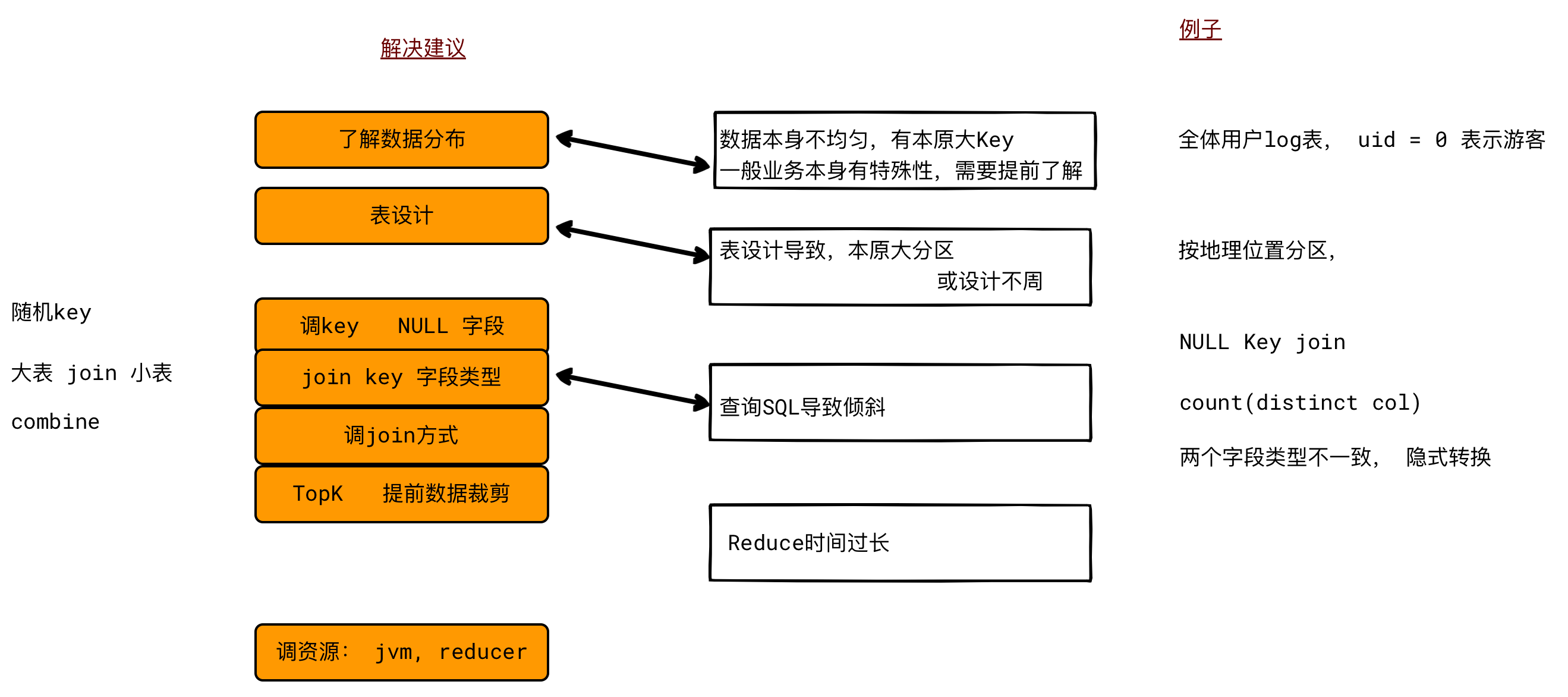
业务数据特性 -
Reduce Key分布不均匀
建表时考虑不周
SQL语句导致
业务数据和建表设计,通过样本分布调查, 是能快速确定或者排除。
补充:
除了MR计算, HDFS的distcp, Sqoop数据同步任务也会出现倾斜。 有机会本文再补充上述的倾斜场景
问题定位
-
关注Stage(Hive或Spark,都有对应的Stage描述)
-
分析Shuffle过程的启动算子
注意groupBy, reduceBy, combineBy, join, distinct等打散MapRDD的操作时用了哪些key。
找到了倾斜发生现场, 进一步要追源头。
分析产生倾斜的原因
源头与上游表设计
- 是否输入源头本来就倾斜?
业务特性导致的不均匀;
数据仓库设计导致的不均匀;
提取逻辑
- 是不是异常Key引起的, 比如有NULL字段、
解决思路:过滤掉NULL值的记录, 或预处理
SQL中的Shuffle处理
-
Join on 条件用到的key
分析 reduce join , map join -
group by / count distinct 字段
处理方式
本源操作
局部优化
map端, hive.map.aggr = true, 在map中做部分的聚集操作
map端, hive.groupby.skewingdata = true, 数据倾斜时启用负载均衡 引入随机key 二次mapreduce
reduce端; hive.exec.reducers.bytes.per.reducer = 1000000000 Hive 默认每个节点处理1G大小数据。
Reduce Join 前置为Map Join 适用于一个表(或RDD)明显小于另一个的场景。
set hive.optimize.skewjoin = true
set hive.skewjoin.key = skew_key_threshold (default )
内存与任务规模优化:
提高shuffle并行度/ 增加Reducer个数
增加Reducer 的JVM内存
自定义分区
SQL语法优化
count(distinct a) count(1) from grouped_A
拆表查询, 将引起倾斜部分的数据单独处理。