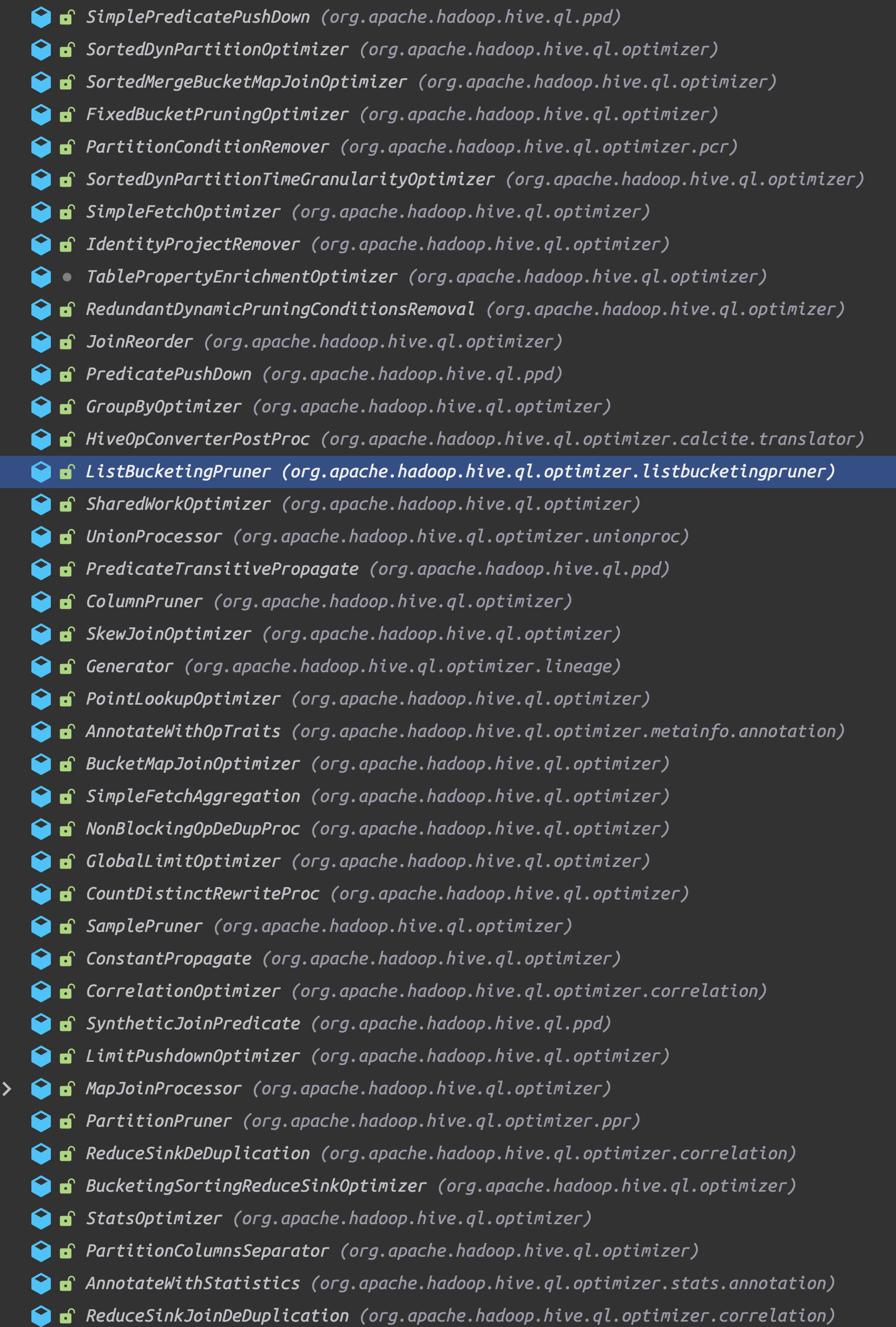
Hive的执行计划
Hive的SQL是怎么转变成的MapReduce
Driver端,
- 将HQL语句转换为AST;
- 借助于 ParseDriver: 将HQL语句转为Token , 对Token解析生成AST;
- 将AST转换为TaskTree;
- SemanticAnalyzer, AST转换为QueryBlock
- 将QB转换为OperatorTree
- 将OT进行逻辑优化, 生成TaskTree
- TaskTree执行物理优化
- 提交任务执行 (ExecDriver)
Hive 的执行入口类
- 主类 CliDriver run() 方法
- 执行executeDriver
- processCmd
- processLocalCmd
- qp.run(cmd)
- runInternal
其中 qp 是Driver对象, Driver端的runInternal 方法, 调用了compile 完成了语法的解析和编译.
compileInternal 编译
编译器, 解析器, 优化器 在这步
AST 在这里生成
compile方法中, 使用ParseUtils.parse 完成对命令的解析,生成一棵AST树,代码如下:
ASTNode tree; // AST 树
tree = ParseUtils.parse(command, ctx);
...
HiveLexerX lexer = new HiveLexerX(new ANTLRNoCaseStringStream(command));
TokenRewriteStream tokens = new TokenRewriteStream(lexer);
Hive 使用ANTLR 完成SQL的词法解析, 在老版本的Hive中, 因为语法非常简单, 只用一个文件 Hive.g 完成,随着语法规则越来越复杂, 目前为拆分成了5个文件:
- 词法规则 HiveLexer.g
- 语法规则 四个文件:
- SelectClauseParser.g
- FromClauseParser.g
- IdentifiersParser.g
- HiveParser.g
AST转为Operator Tree
- Implementation of the semantic analyzer. It generates the query plan.
- There are other specific semantic analyzers for some hive operations such as
- DDLSemanticAnalyzer for ddl operations.
优化器
// SemanticAnalyzer.java
Optimizer optm = new Optimizer();
轮询Optimizer中的优化策略
// Optimizer.java
// Invoke all the transformations one-by-one, and alter the query plan.
public ParseContext optimize() throws SemanticException {
for (Transform t : transformations) {
t.beginPerfLogging();
pctx = t.transform(pctx);
t.endPerfLogging(t.toString());
}
return pctx;
}
这个Transform 就是优化策略的抽象类,
例如GroupByOptimizer 是有条件地执行map侧计算,减少shuffle IO.
This transformation does group by optimization. If the grouping key is a superset of the bucketing and sorting keys of the underlying table in the same order, the group by can be performed on the map-side completely.
execute() 执行
执行器
Hive- Explain
最简单的Explain计划例子
只有一个Stage, 即Stage-0, 而且是一个Fetch Operator, limit为负1 表示没有Limit操作.
Processor树下面只有一个TableScan, 是对表名 logs的操作.
统计信息能看到 一共的行数,(Num rows), 数据尺寸(Data size). Select算子下面是执行的扫列, 因为执行了select *, 所以全部列的schema都展示出来了.
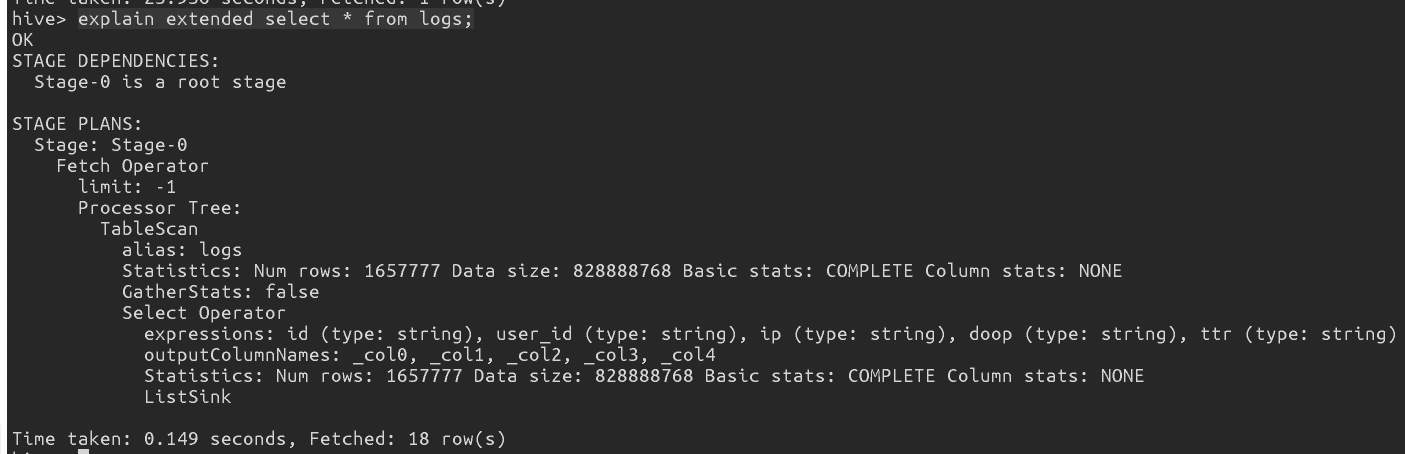
一个稍稍复杂的例子
再来看一个带有 分组聚合查询(count + count distinct)的例子
执行语句是
hive> explain extended select ip , count(distinct id) uv, count( doop) pv from logs group by ip;
阶段划分为2个了, Stage 1是 根阶段, Stage 0 依赖于Stage1
Stage1是一个Map Reduce阶段,分为 Map树
Map过程也是要执行TableScan, 扫的logs表-行数列数, 执行 Select, 只对 ip id 和 doop 三列扫. GroupBy 算子
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: logs
Statistics: Num rows: 2762962 Data size: 828888768 Basic stats: COMPLETE Column stats: NONE
GatherStats: false
Select Operator
expressions: ip (type: string), id (type: string), doop (type: string)
outputColumnNames: ip, id, doop
Statistics: Num rows: 2762962 Data size: 828888768 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count(DISTINCT id), count(doop)
keys: ip (type: string), id (type: string)
mode: hash
outputColumnNames: _col0, _col1, _col2, _col3
Statistics: Num rows: 2762962 Data size: 828888768 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string), _col1 (type: string)
null sort order: aa
sort order: ++
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 2762962 Data size: 828888768 Basic stats: COMPLETE Column stats: NONE
tag: -1
value expressions: _col3 (type: bigint)
auto parallelism: false
Path -> Alias:
file:/Users/staticor/tmp/hive/warehouse/shopee.db/logs [logs]
Path -> Partition:
file:/Users/staticor/tmp/hive/warehouse/shopee.db/logs
Partition
base file name: logs
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
properties:
bucket_count -1
column.name.delimiter ,
columns id,user_id,ip,doop,ttr
columns.comments
columns.types bigint:bigint:string:string:string
file.inputformat org.apache.hadoop.mapred.TextInputFormat
file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
location file:/Users/staticor/tmp/hive/warehouse/shopee.db/logs
name shopee.logs
numFiles 1
numRows 0
rawDataSize 0
separatorChar
serialization.ddl struct logs { i64 id, i64 user_id, string ip, string doop, string ttr}
serialization.format 1
serialization.lib org.apache.hadoop.hive.serde2.OpenCSVSerde
totalSize 828888758
transient_lastDdlTime 1653360838
serde: org.apache.hadoop.hive.serde2.OpenCSVSerde
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
properties:
bucket_count -1
column.name.delimiter ,
columns id,user_id,ip,doop,ttr
columns.comments
columns.types bigint:bigint:string:string:string
file.inputformat org.apache.hadoop.mapred.TextInputFormat
file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
location file:/Users/staticor/tmp/hive/warehouse/shopee.db/logs
name shopee.logs
numFiles 1
numRows 0
rawDataSize 0
separatorChar
serialization.ddl struct logs { i64 id, i64 user_id, string ip, string doop, string ttr}
serialization.format 1
serialization.lib org.apache.hadoop.hive.serde2.OpenCSVSerde
totalSize 828888758
transient_lastDdlTime 1653360838
serde: org.apache.hadoop.hive.serde2.OpenCSVSerde
name: shopee.logs
name: shopee.logs
Truncated Path -> Alias:
/shopee.db/logs [logs]
Needs Tagging: false
Reduce Operator Tree:
Group By Operator
aggregations: count(DISTINCT KEY._col1:0._col0), count(VALUE._col1)
keys: KEY._col0 (type: string)
mode: mergepartial
outputColumnNames: _col0, _col1, _col2
Statistics: Num rows: 1381481 Data size: 414444384 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
GlobalTableId: 0
directory: file:/Users/staticor/tmp/hive/9ae192bf-f90d-4427-ba16-54d05ac3c8a3/hive_2022-05-29_16-51-04_737_1249285988661867765-1/-mr-10001/.hive-staging_hive_2022-05-29_16-51-04_737_1249285988661867765-1/-ext-10002
NumFilesPerFileSink: 1
Statistics: Num rows: 1381481 Data size: 414444384 Basic stats: COMPLETE Column stats: NONE
Stats Publishing Key Prefix: file:/Users/staticor/tmp/hive/9ae192bf-f90d-4427-ba16-54d05ac3c8a3/hive_2022-05-29_16-51-04_737_1249285988661867765-1/-mr-10001/.hive-staging_hive_2022-05-29_16-51-04_737_1249285988661867765-1/-ext-10002/
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
properties:
columns _col0,_col1,_col2
columns.types string:bigint:bigint
escape.delim \
hive.serialization.extend.additional.nesting.levels true
serialization.escape.crlf true
serialization.format 1
serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
TotalFiles: 1
GatherStats: false
MultiFileSpray: false
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
Time taken: 0.159 seconds, Fetched: 123 row(s)
hive.fetch.task.conversion=more
控制哪些查询走MapReduce
none, 所有查询都走MR;
more, 默认Level, 查询字段,分区的where, limit 时间戳, 虚拟字段
minimal, 查询字段, 分区的where, limit 不走MR
一个简单的count (distinct ) + sum 的单表执行计划:
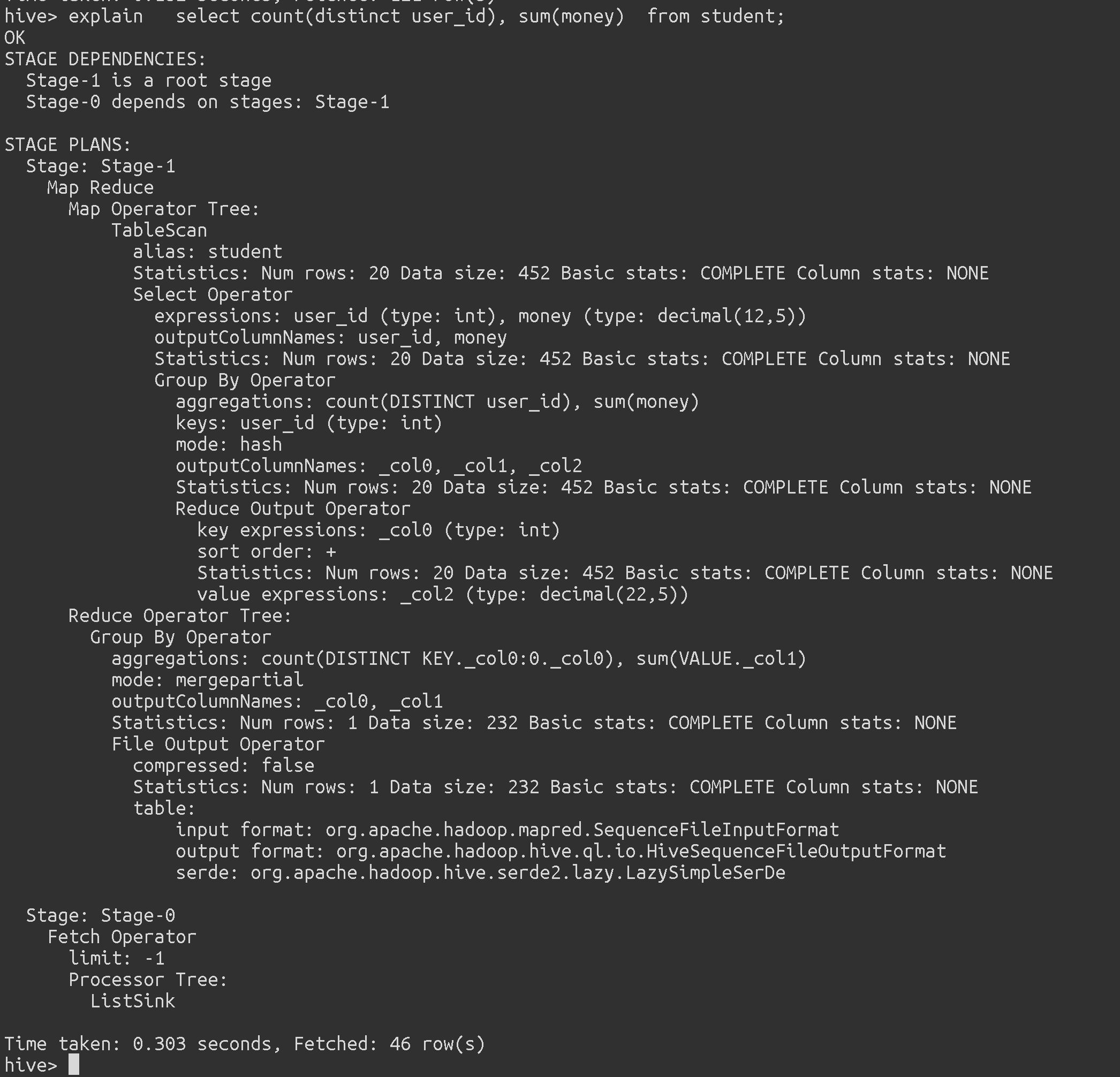
Stage 0 依赖于Stage1,
Stage1 执行了MapReduce,
Map阶段执行操作:
表扫描,
字段映射Project(Select Operator)
聚合