OneData与OneService 初识
OneData OneService,统一数据管理,统一数据服务。
大型公司的数据部门最终发展方向是面向公司的数据使用者提供一个稳定可靠的数据平台,真正发挥数据的价值,而不单是成本。
数据资产的意义是沉淀+挖掘,可以形成有价值的业务决策。 成本是消耗性质的,难以复用和被挖掘的。
几万张表最基本的分类是按业务域和主题域进行逻辑上的划分。
例如表名:
dwd.wms_inbound_order_info_di
dwd是数据明细层,物理分层标识;
wsm是仓储主题域的缩写;
inbound表示产品入库业务过程;
order_info是事实表名称;
di是存量增量后缀符,表示按日增量表
数据架构
存储 + 集成 + 计算 + 服务 + 治理
以Hadoop为代表性的大数据集群,Hadoop(包含HBase)是负责数据的存储工作。
Hadoop之上是和外部系统的数据管道对接服务(集成模块):Flume,Sqoop,Datax,Kafka。
另外便是计算引擎层Hive,Spark,Flink,这些跑在Hadoop之上的数据作业,一般是以一棵棵任务调度树的形式运转,用web-ui的方式组织(Airflow,Azkaban)
数据服务层是将生产加工出的数据(离线或实时)投递到对应的展现层,包装成数据产品。
数据治理,则是围绕着元数据中心进行数据地图、血缘关系、数据字典、指标系统、权限管理进行。
我认为企业的数据仓库组织架构发展存在这几个阶段:
一草根时期,无名义上的数据仓库工作者,由运营或分析师处理公司的必要数据需求;此时基本上没有Hadoop集群; 二小型大数据部门(10人),分配3-5人进行数据仓库工作,3-5人进行数据服务与平台开发工作。 此时多是以高效完成业务数据需求为主,对数据质量和治理花的功夫不多。
三多点开花,随着业务扩张或公司规模发展,开始划分出多个业务自治的数据仓库。 多个分散小数仓各自为战,灵活效率支撑业务需求。 四分久必合。成立数据中台项目,形成统一的公共数据仓库层。自然,这个过程也就说明公司技术部门在数据上的资源是加大投入的,要有专职的数据产品部门、数据开发团队和平台架构部门的配合,才得以完成。
metadata
公司元数据应包含哪些内容?
数据字典 [data dictionary]
数据结构体为: 库名-表名,表中各字段名、数据类型和备注

血缘关系 [data lineage]
血缘关系是指表的加工依赖,一般是可以看到一张倒树图:
其它,数据特征
目前业内有影响力的元数据产品,Netflix-Metacat,Apache Atlas,Cloudera Navigator.
元数据管理的组成部门:
- 数据源管理: MySQL,MongoDB,Hive,Kudu ...
- 血缘解析:解析SQL,提出目标表和依赖的输入表。
很久以前,我自己也实现过简单的Python parser脚本(正则解析),完成一个SQL脚本的表名解析。
这也是一种最简单的解析SQL方式:静态解析。 除此之外还可以实时抓取执行SQL的计划,获取输入和输出。
以及第三种,根据任务日志再解析。
数据血缘是数据生命周期管理的前提,便于实现数据级别和数据安全(访问权限控制)。
Netflix的元数据管理实践
阅读了一篇Medium的技术文章(2018年)
Metacat: Making Big Data Discoverable and Meaningful at Netflix
早期Netflix是使用Hive+Pig进行数据ETL,数据源涉及Amazon S3,Druid,ES,Redshift,Snowflake和MySQL。
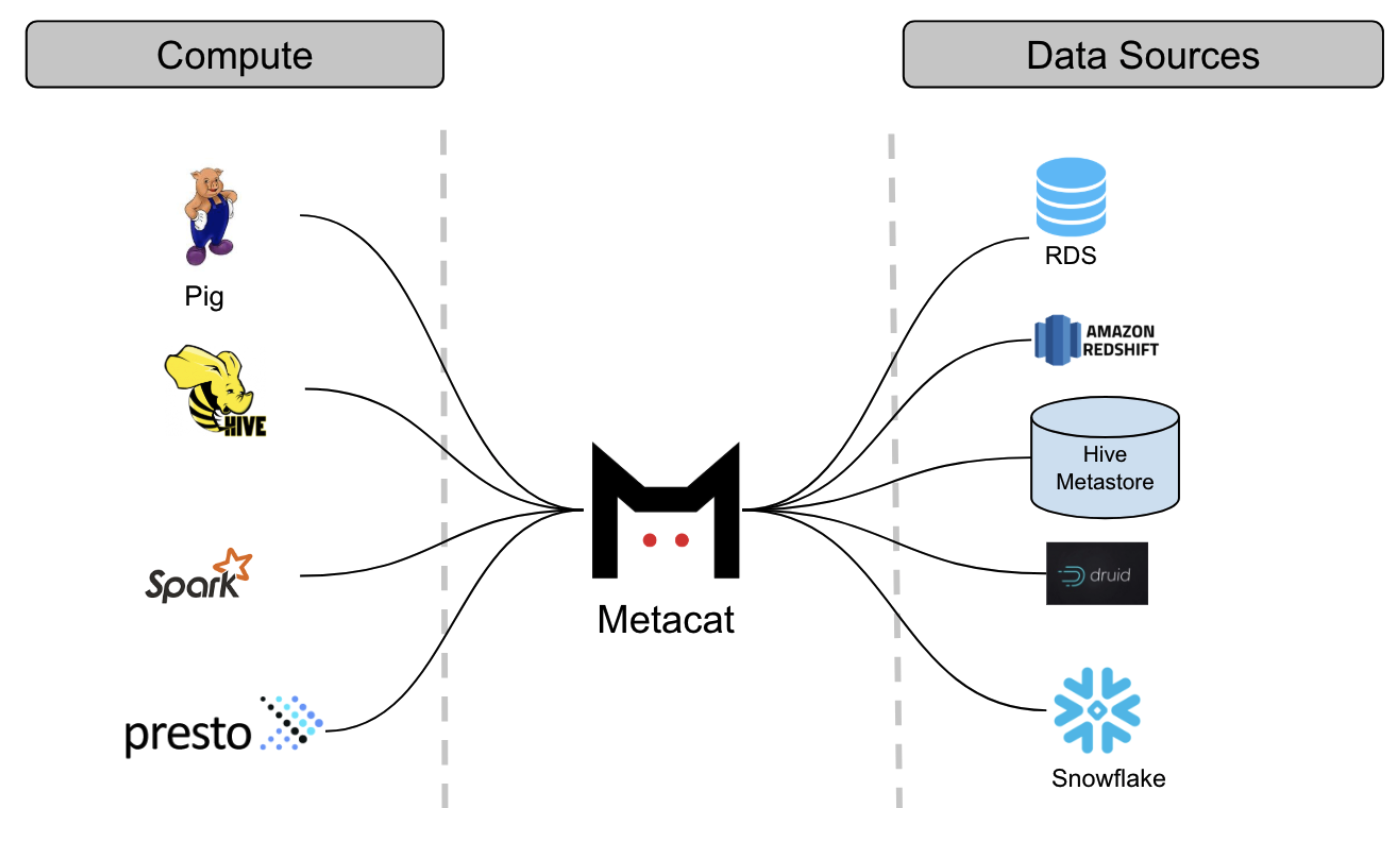
Metacat是通过一套统一的REST/Thrift接口,访问各种不同的数据源。
The respective metadata stores are still the source of truth for schema metadata,
so Metacat does not materialize it in its storage.
It only directly stores the business and user-defined metadata about the datasets.
It also publishes all of the information about the datasets to Elasticsearch for full-text search and discovery.
可见Metacast直接抽取上游的元数据,不再单独的实现。同时提供ES的检索功能。
以Hive元数据为例,Hive的元数据托管在RDBMS(MySQL),有可能成为Hive服务的瓶颈。
所以额外的数据读取服务需要重新设计,以避免对Hive作业造成影响。
(例如对元数据读写造成的锁冲突问题)
OneService
数据服务是面向数据需求。
满足数据需求的方式由数据产品和业务方与开发人员协商,最终确定实现。
在这个过程中离不开数据的开发和服务的稳定。
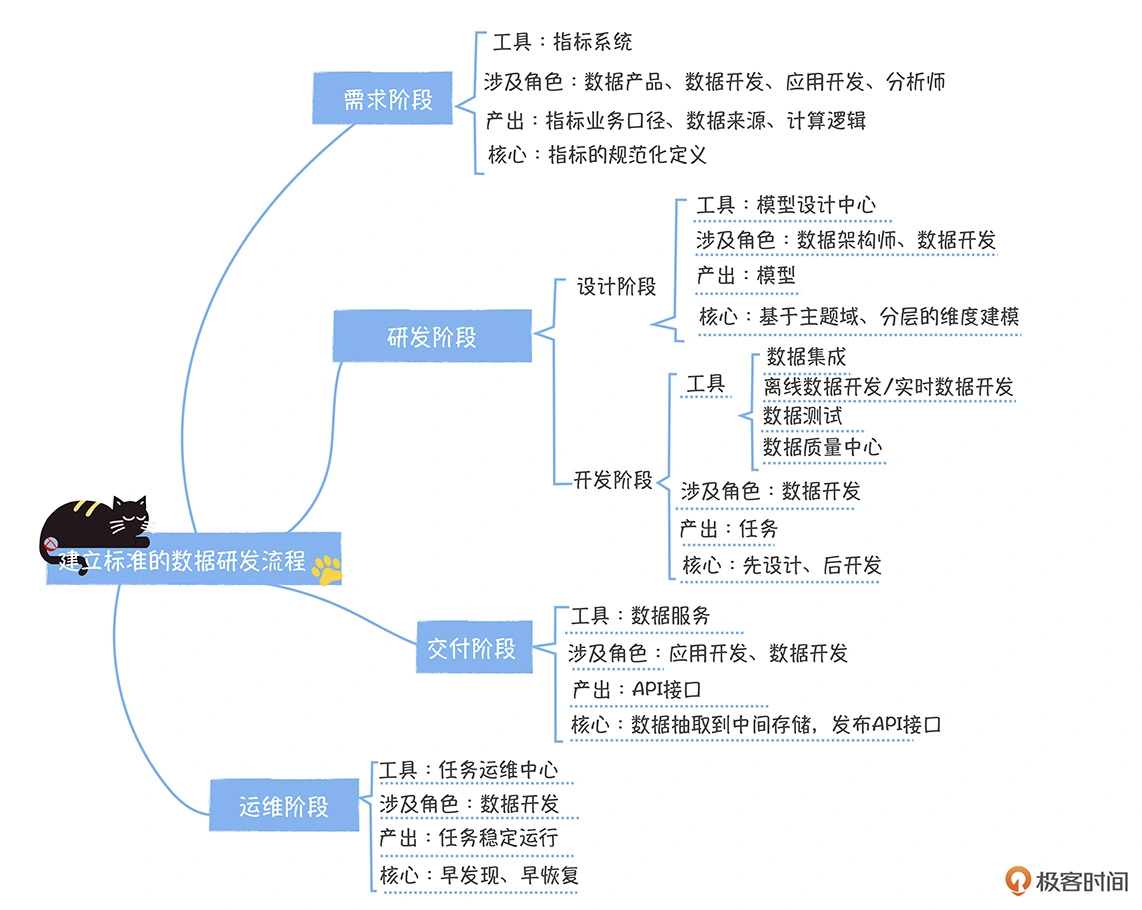
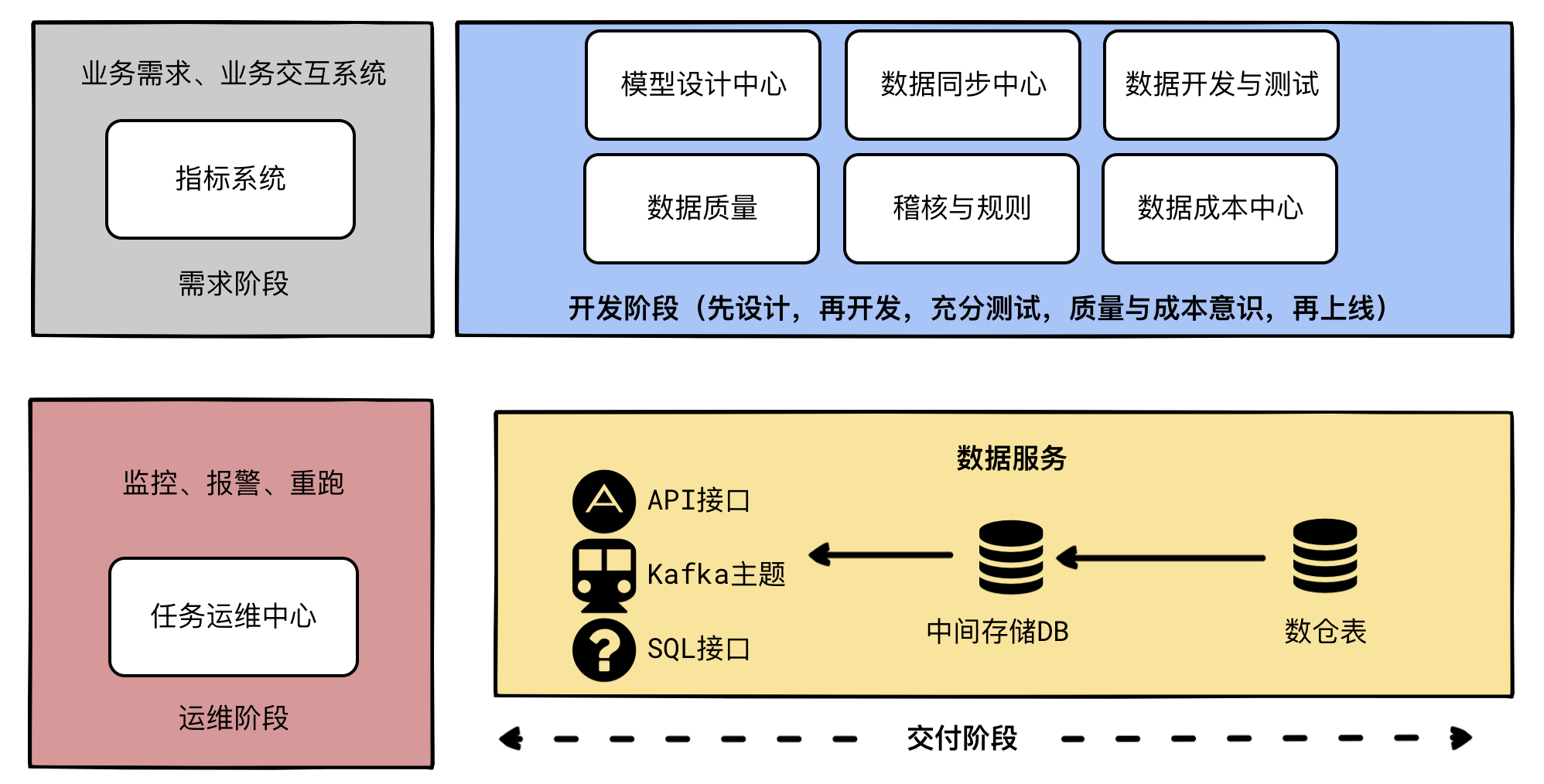
数据研发流程要考虑的角色和阶段: