[Paper]Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
Abstract
我们提出了RDD, 弹性分布式数据集 ---- 一种分布式内存的抽象结构, 允许程序员以容错方式在大型集群上执行内存计算. 在当前计算框架下,有两种类型的计算应用表现性能较低: 迭代式算法和交互式数据挖掘, RDD也是受到了启发,从而产生.
这两种情况下,将数据保存在内存可以将性能提高一个数量级.
RDD提供了一种受限制的内存共享机制,基于对共享状态粗粒度的转换,而不是细粒度更新.
然而, 我们证明RDD的表达能力是足以覆盖很多计算场景的.
Introduction
MapReduce和Dryad等诸框架已经被大规模应用,这些系统让用户使用一系列高级别的算子完成并行计算,不必担心工作的分发和容错.
但它们缺少了对于内存的抽象,导致效率低.
Data复用在很多地方上是必要的: PageRank, K-Means 聚类, LR回归.
交互数据挖掘, 频繁对数据进行ad-hoc. 可惜, 像MapReduce是满足不了这两类场景的.
MR在HDFS上的计算任务,会产生大量的IO\ 序列化和数据备份,严重影响了任务的开销.
认识到这个问题,研究者提出了一些data reuse的方案 : Prege, HaLoop
它们的局限性是仅适用于特定计算场景.
本论文提出的RDD具备更宽的使用范围.
RDD是容错的,并行数据结构,封装了一系列的灵活算子,可以在内存完成各自任务.
RDD设计的主要挑战是编程接口的容错设计.
目前存在的集群内存存储设计: DSM(Distributed Shared Memory), Database, Piccolo,是通过对状态的细粒度更新,提供了接口.
RDD是基于 粗粒度的接口设计.
RDD
RDD的抽象设计
只读的,带有分区.
创建方式有二: 只能从指定存储的数据结构或者由别的RDD变换而来, 我们称这些变换为特定的"transformation" 算子.
典型的例子, map, filter, join.
RDD 不需要在任何时刻都被实现, RDD拥有足够的信息,证明自己是怎么派生出来的(从其它数据集), 这是一个很便利的属性. 本质上, 一个程序不能引用一个RDD (如果它重建失败了)
Spark 编程接口
map, filter
Actions: count, collect, save
除此之外,还提供 persist 方法.
Spark默认将RDD保存在内存,但如果内存不够,可以指定别的存储策略.
例子, Console Log Mining 控制台日志分析
想在HDFS已有的日志(TB级)检索信息.
使用Spark, 会将这些日志分段加载到不同的节点
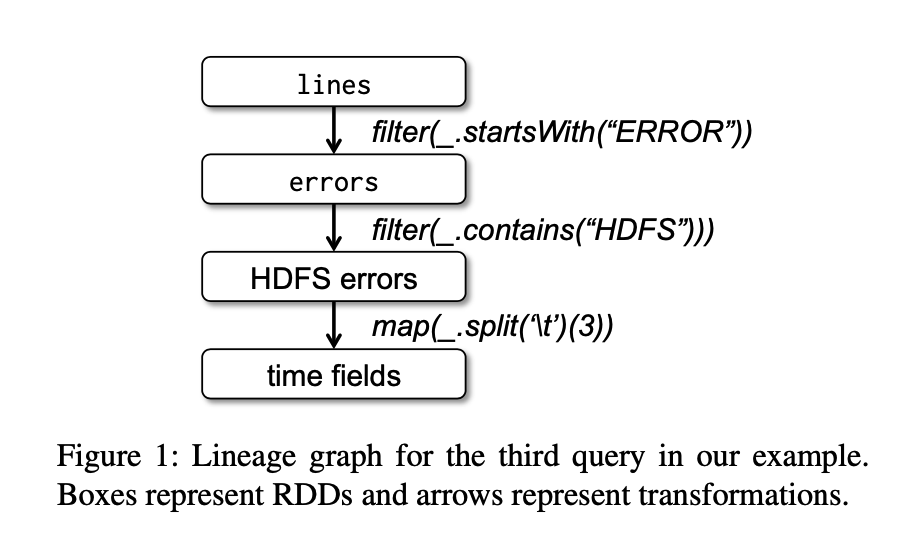
lines = spark.textFile("hdfs:// ...path...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
errors.filter(_.contains("MySQL")).count()
errors.filter(_.contains("HDFS"))
.map(_.split('\t')(3))
.collect()
pipeline 作业, 把任务分发到持有errors分区的节点上.
RDD vs. Distributed Shared Memory
DSM(是什么), 可以全局的进行读写.
RDD和DSM的主要区别: RDD只能由粗变换创建, DSM可以对单个内存地址读写(RDD可以视作是一片连续区域?)
RDD限制了批量写的程序,但可以更有效的容错.
特别地,RDD不用产生检查点,因为它们可以使用血缘来快速恢复.
只有当RDD失败时才会重算(并行的在其它节点完成),不必重头回滚整个程序.
RDD的第二个特性,不可变性. 系统通过运行慢任务备份副本来缓解慢节点.
RDD不适合的应用场景
通过前面的介绍,RDD是适合于批量计算的应用,也适合于一步接一步的迭代式计算.
但对于流计算, RDD不适用的.
Spark Programming Interface
Spark使用Scala,提供了像 DryadLINQ 一样的 API.
Scala是函数式编程语言, 然而RDD倒不必须使用FP来实现.
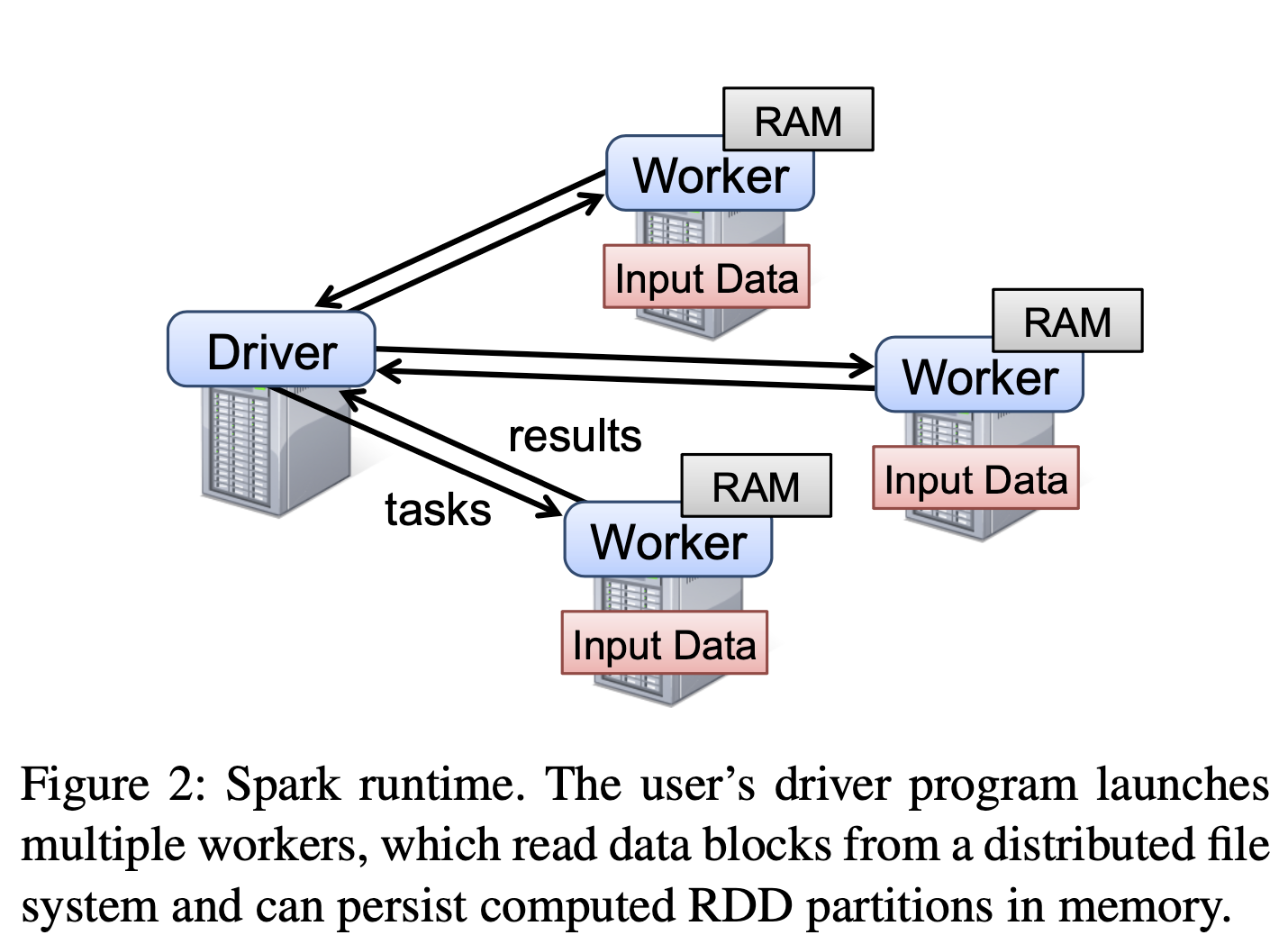
Spark, 开发者需要完成一个 driver program, 与一系列workers集群通信, 如下图:
编程接口

val points = spark.textFile(... ) .map(parseFunc).persist()
var w = // random
for( i <- 1 to ITERATIONS) {
val gradient = points.map {
p.x * (1/ ...)
}.reduce( (a, b) => a+b )
w -= gradient
}
RDD 的表示
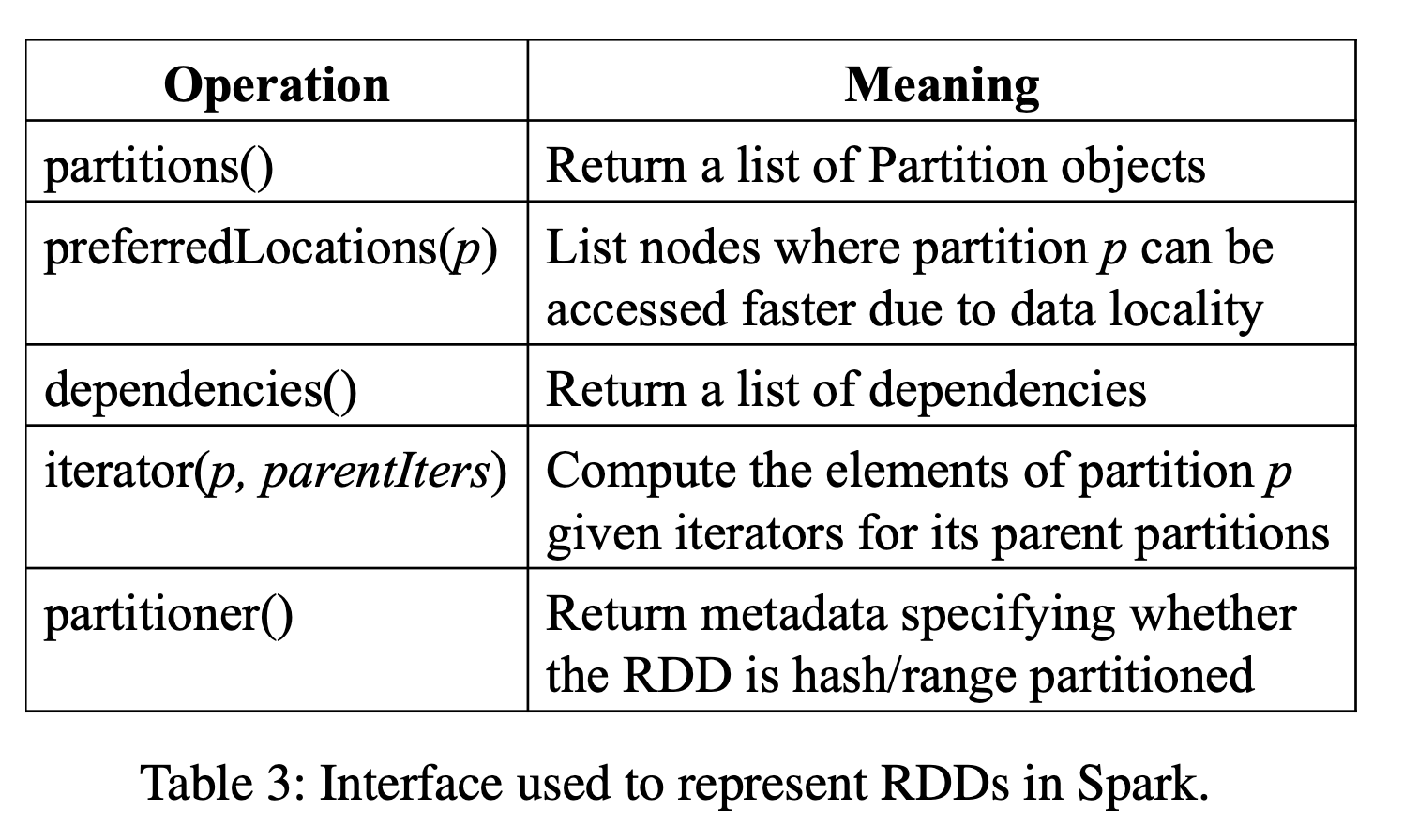
提供了通用的五个特征:
- partitions 分区, 数据集的最小操作原子单位. 返回一组分区列表
- dependencies 依赖, RDD是怎么来的 返回一组依赖的列表
- partitioner 返回metadata, return metadata 这个RDD是Hash分区还是Range分区.
- metadata 分区,schema信息
- data placement 数据放置信息 preferredLocation(p) 节点列表, 参数是p(分区), 返回能访问它的节点
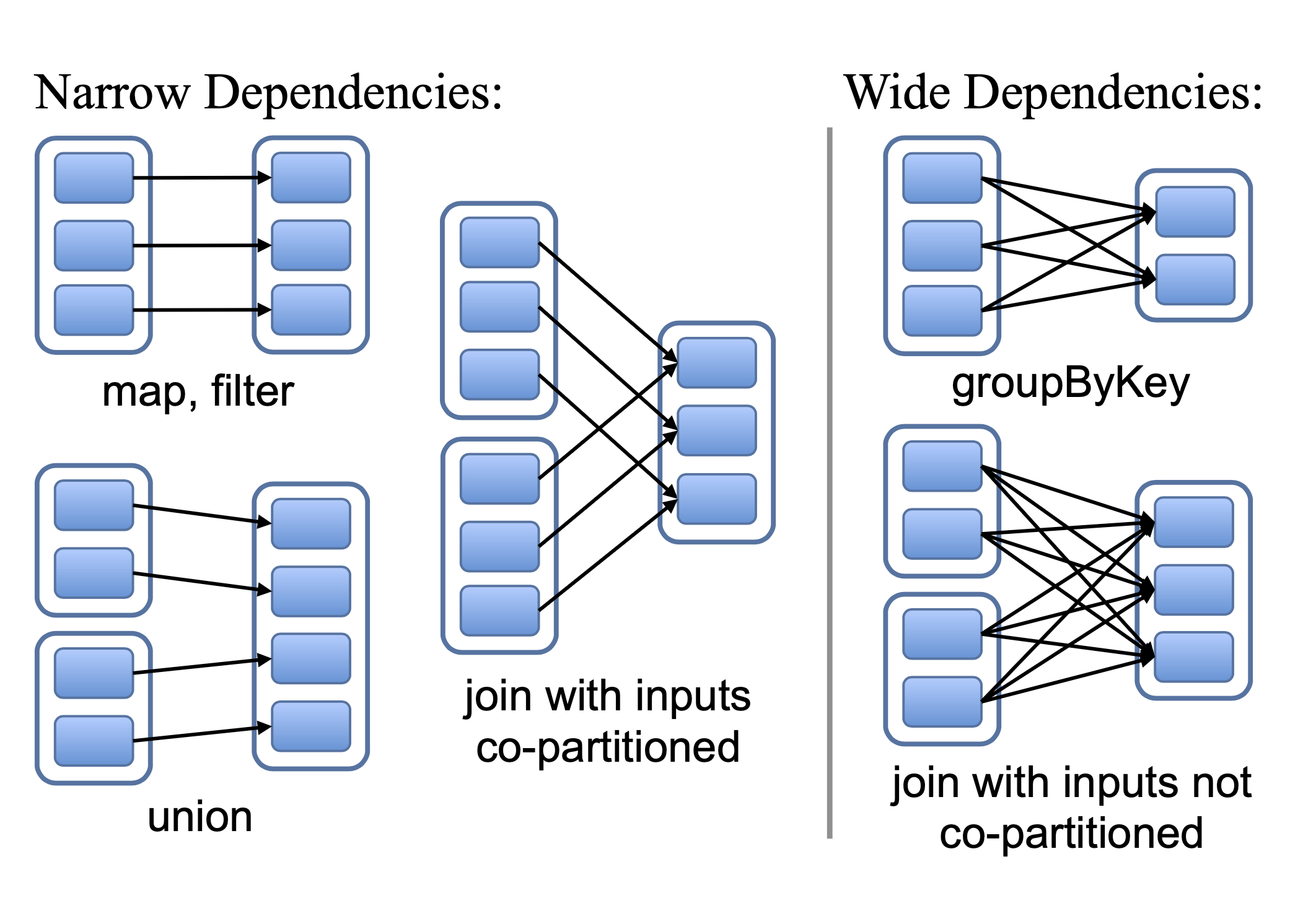
对RDD而言,有意思的便是设计不同RDD的依赖关系.
我们定义了两类, 窄依赖和宽依赖.
窄依赖,每个父RDD的分区,最多被一个子RDD依赖. 例如 map是窄依赖的操作
宽依赖则是一个RDD的分区被多个子RDD依赖, 例如 join是宽依赖操作.
窄依赖可以在一个节点上形成执行流水线作业(map, filter + ..) 都是element by element.
对比来说,宽依赖需要收集所有依赖的父分区数据.
窄依赖可以快速重算.
在宽依赖下,如果单节点计算失败了,就需要再次重上游依赖提取数据重计算,恢复成本较高.
实现
大约使用了14000行Scala代码完成了Spark的实现.
能运行在Mesos集群,Hadoop共享资源的应用.
Job Scheduling
分配任务时, 将任务分发到哪一台机器上考虑了 data locality. 就近
对于宽依赖(shuffle 依赖), 目前我们采用的是这种方式, 在父分区所在节点,存储中间结果,以简化故障恢复, 有些类似MapReduce时对Map output的设计.
如果一个任务失败了, 会在别的节点上 rerun.
如果某一个Stage不可用了, (比如 从Mapside 产生的shuffle write 结果丢了), 会重新提交丢失的分区.
Interpreter Intergration
解释器集成
two changes
- Class Shipping,
- Modified code generation
Memory Management 内存管理
Spark 提供了三个RDD持久化的级别,
- 在内存持久化(以Java 反序列化对象)
- 在内存以序列化对象
- 在硬盘
第一种性能最好, JVM可以直接访问RDD.
第二种 允许用户在空间有限时, 比Java对象更节省空间的方式表示, 但性能不如第一种.
第三种, 当RDD太大时, 每次都用内存开销太高. 因此在内存上更为方便
为了更好利用内存,我们使用LRU的丢弃机制.
当新的RDD分区被计算, 而且没有足够空间存储它, 我们会将最久不使用的RDD丢弃.