Spark的执行计划
A Deep Dive into Spark SQL's Catalyst Optimizer -- Yin Huai
https://databricks.com/session/a-deep-dive-into-spark-sqls-catalyst-optimizer
A Deep Dive into Query Execution Engine of Spark SQL - Maryann Xue
Spark Execution plan
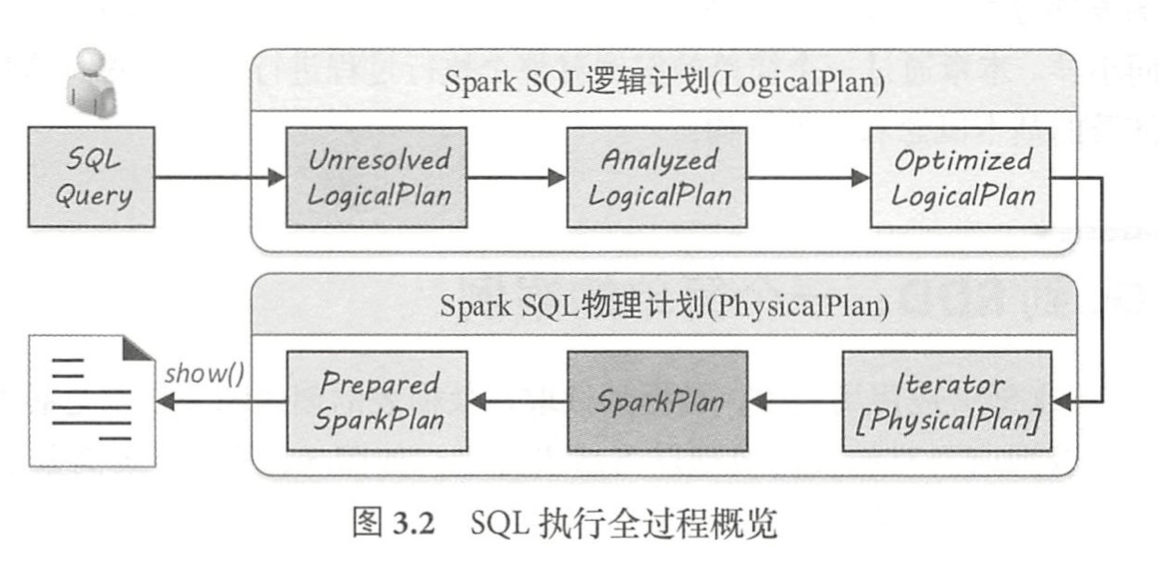
在MySQL的Server会将用户提交的query进行解析和分析优化,转变为执行任务。 在Hive和Spark SQL的工作流程中,也会有类似的过程。
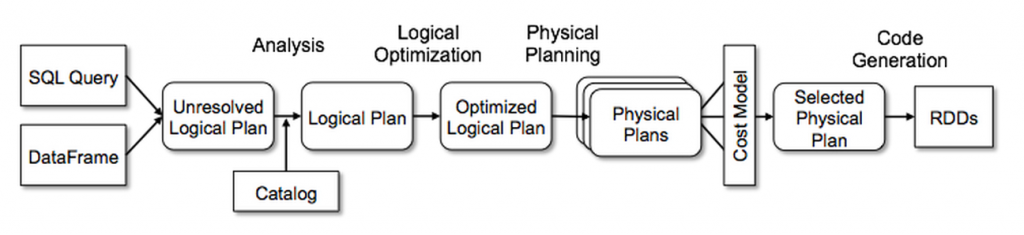
- Analysis
- Unresolved Logical plan
- Catalog
- Logical Plan
- Logical Optimization
- Optimized Logical Plan
- Physical Planing
- Physical plans
- Cost Model
- Code Generation
不妨先用一个引子来看看Plan是什么,怎样看到它。
val schemaItems: StructType = StructType(List(
StructField("itemid", IntegerType, nullable = false),
StructField("itemname", StringType, nullable = false),
StructField("price", DoubleType, nullable = false),
))
val itemRDD: RDD[Row] = spark.sparkContext.parallelize(Seq(
Row(1, "Tomato", 4.5),
Row(2, "Potato", 3.5),
Row(0, "Watermelon", 14.5),
))
val schemaOrders: StructType = StructType(List(
StructField("userid", IntegerType, nullable = false),
StructField("itemid", IntegerType, nullable = false),
StructField("count", IntegerType, nullable = false),
))
val orderRDD: RDD[Row] = spark.sparkContext.parallelize(Seq(
Row(100, 0 , 1),
Row(100, 1, 1),
Row(101, 2, 3),
Row(102, 2, 8),
))
val itemDF = spark.createDataFrame(itemRDD, schemaItems)
val orderDF = spark.createDataFrame(orderRDD, schemaOrders)
itemDF.createTempView("items")
orderDF.createTempView("orders")
itemDF.show()
orderDF.show()
// itemDF.join(orderDF, "itemDF.itemid == orderDF.itemid").show()
val x: DataFrame = spark.sql(
"""
|select items.itemname, sum(1) as pv, sum(orders.count) as totalcount
|from items, orders
|where items.itemid = orders.itemid
|group by items.itemname
|""".stripMargin)
x.explain()
在控制台能看输出的结果: 其中explain的参数分为三类
-- 无参数类型
x.explain() // 等于 SimpleMode
-- Boolean类型
explain(mode=”simple”) which will display the physical plan
x.explain(true) // 开为true之后中, 会显示 物理plan+逻辑plan
-- String类型: extended / codegen / cost / formatted
explain(mode=”extended”) which will display physical and logical plans (like “extended” option)
explain(mode=”codegen”) which will display the java code planned to be executed
explain(mode=”cost”) 打印出 逻辑计划和统计。
explain(mode=”formatted”) 分为两个section: 物理计划和节点

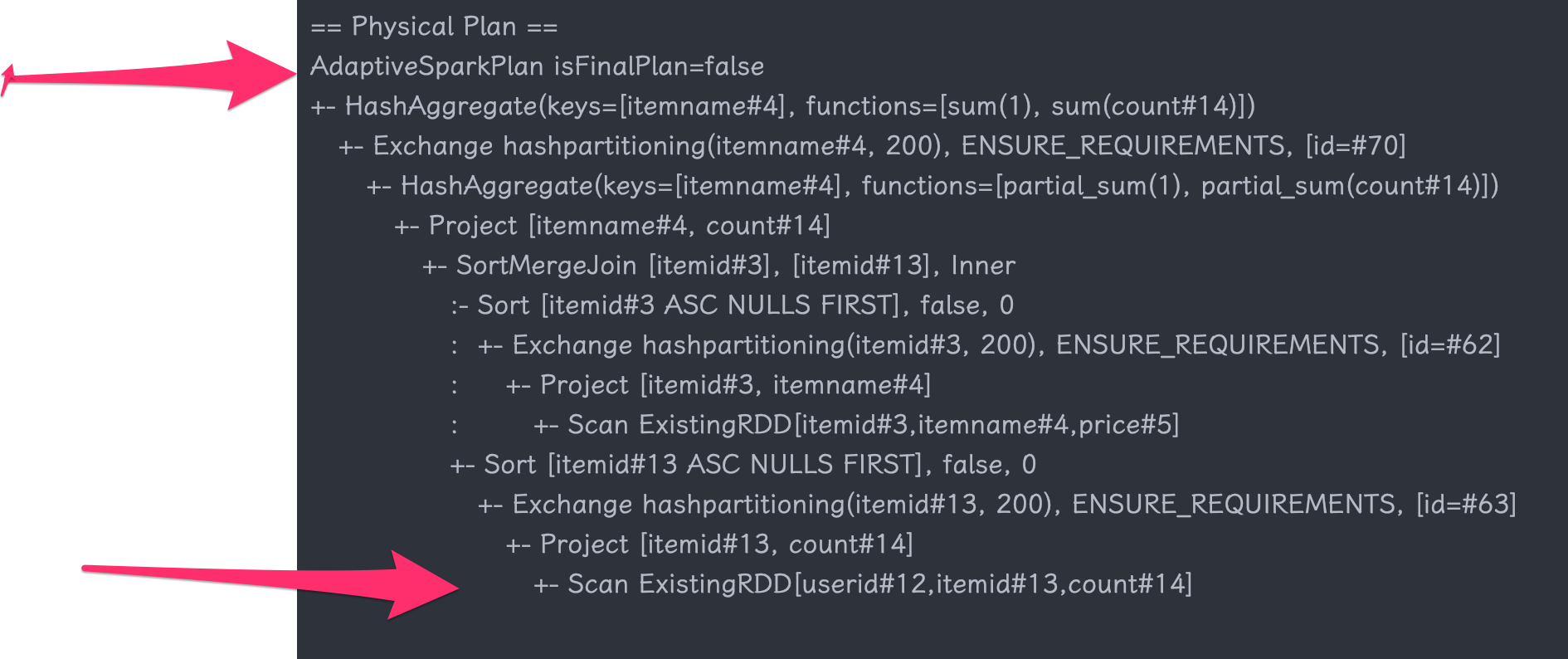
以formatted为例的输出
== Physical Plan ==
AdaptiveSparkPlan (14)
+- HashAggregate (13)
+- Exchange (12)
+- HashAggregate (11)
+- Project (10)
+- SortMergeJoin Inner (9)
:- Sort (4)
: +- Exchange (3)
: +- Project (2)
: +- Scan ExistingRDD (1)
+- Sort (8)
+- Exchange (7)
+- Project (6)
+- Scan ExistingRDD (5)
(1) Scan ExistingRDD
Output [3]: [itemid#3, itemname#4, price#5]
Arguments: [itemid#3, itemname#4, price#5], MapPartitionsRDD[2] at createDataFrame at MustKnowAboutQueryPlan.scala:44, ExistingRDD, UnknownPartitioning(0)
(2) Project
Output [2]: [itemid#3, itemname#4]
Input [3]: [itemid#3, itemname#4, price#5]
(3) Exchange
Input [2]: [itemid#3, itemname#4]
Arguments: hashpartitioning(itemid#3, 200), ENSURE_REQUIREMENTS, [id=#62]
(4) Sort
Input [2]: [itemid#3, itemname#4]
Arguments: [itemid#3 ASC NULLS FIRST], false, 0
(5) Scan ExistingRDD
Output [3]: [userid#12, itemid#13, count#14]
Arguments: [userid#12, itemid#13, count#14], MapPartitionsRDD[3] at createDataFrame at MustKnowAboutQueryPlan.scala:45, ExistingRDD, UnknownPartitioning(0)
(6) Project
Output [2]: [itemid#13, count#14]
Input [3]: [userid#12, itemid#13, count#14]
(7) Exchange
Input [2]: [itemid#13, count#14]
Arguments: hashpartitioning(itemid#13, 200), ENSURE_REQUIREMENTS, [id=#63]
(8) Sort
Input [2]: [itemid#13, count#14]
Arguments: [itemid#13 ASC NULLS FIRST], false, 0
(9) SortMergeJoin
Left keys [1]: [itemid#3]
Right keys [1]: [itemid#13]
Join condition: None
(10) Project
Output [2]: [itemname#4, count#14]
Input [4]: [itemid#3, itemname#4, itemid#13, count#14]
(11) HashAggregate
Input [2]: [itemname#4, count#14]
Keys [1]: [itemname#4]
Functions [2]: [partial_sum(1), partial_sum(count#14)]
Aggregate Attributes [2]: [sum#51L, sum#52L]
Results [3]: [itemname#4, sum#53L, sum#54L]
(12) Exchange
Input [3]: [itemname#4, sum#53L, sum#54L]
Arguments: hashpartitioning(itemname#4, 200), ENSURE_REQUIREMENTS, [id=#70]
(13) HashAggregate
Input [3]: [itemname#4, sum#53L, sum#54L]
Keys [1]: [itemname#4]
Functions [2]: [sum(1), sum(count#14)]
Aggregate Attributes [2]: [sum(1)#46L, sum(count#14)#47L]
Results [3]: [itemname#4, sum(1)#46L AS pv#44L, sum(count#14)#47L AS totalcount#45L]
(14) AdaptiveSparkPlan
Output [3]: [itemname#4, pv#44L, totalcount#45L]
Arguments: isFinalPlan=false
Process finished with exit code 0
Spark SQL 解析器 - Parser
Spark使用 ANTLR(Another Tool for Language Recognition) 4 进行语法的解析.
关于ANTLR4,我还了解不多. 先加到TODO吧.
这部分要重点看 Expressions.
LogicalPlan
逻辑计划在执行计划中是承前启后的作用,SparkSqlParser 中AstBuilder执行节点访问地,将语法树的Context节点转换成对应的LogicalPlan节点 , 生成一棵未解析的逻辑算子树(Unresolved LogicalPlan)
第二阶段, 由Analyzer将一系列规则作用在这个Unresolved LogicalPlan上,对树节点绑定各种数据信息, 生成解析后的逻辑算子树 Analyzed LogicalPlan.
第三阶段执行优化器 Optimizer.
QueryPlan 是 LogicalPlan的父类, 主要操作分为6个模块: 输入输出,字符串,规划化,表达式操作,基本属性和约束.
QueryPlan的方法,
- output 虚函数
- outputSet 封装output返回值, 返回AttributeSet
- inputSet, 节点输入是所有子节点的输出, 返回值也是 返回AttributeSet
- produceAttributes 该节点产生的属性;
- missingInput 该节点表达式涉及的, 但子节点输出不包含的属性
各阶段Plan的角色
Unresolved Logical Plan
- syntactic field check
- 语义分析, 生成第一版logical plan
此时的plan 还不会下探到字段级别, 如下面所示。
== Parsed Logical Plan ==
'Aggregate ['items.itemname], ['items.itemname, 'sum(1) AS pv#44, 'sum('orders.count) AS totalcount#45]
+- 'Filter ('items.itemid = 'orders.itemid)
+- 'Join Inner
:- 'UnresolvedRelation [items], [], false
+- 'UnresolvedRelation [orders], [], false
Analyzed Logical Plan
通过Spark Catalog获取Schema信息,包括字段的名称和类型,
参考下面, 会看到RDD的字段名称已经显示出来了。
== Analyzed Logical Plan ==
itemname: string, pv: bigint, totalcount: bigint
Aggregate [itemname#4], [itemname#4, sum(1) AS pv#44L, sum(count#14) AS totalcount#45L]
+- Filter ((itemid#3 = itemid#13) AND (price#5 > cast(2 as double)))
+- Join Inner
:- SubqueryAlias items
: +- View (`items`, [itemid#3,itemname#4,price#5])
: +- LogicalRDD [itemid#3, itemname#4, price#5], false
+- SubqueryAlias orders
+- View (`orders`, [userid#12,itemid#13,count#14])
+- LogicalRDD [userid#12, itemid#13, count#14], false
Optimized Logical Plan
? Optimized的rule有哪些? 待补充。
观察Filter算子 在上一个Plan中出现在Join之前, Predicate Pushdown发生在这里。
优化之后,Filter算子下推到了Join内部的流程。
== Optimized Logical Plan ==
Aggregate [itemname#4], [itemname#4, sum(1) AS pv#44L, sum(count#14) AS totalcount#45L]
+- Project [itemname#4, count#14]
+- Join Inner, (itemid#3 = itemid#13)
:- Project [itemid#3, itemname#4]
: +- Filter (price#5 > 2.0)
: +- LogicalRDD [itemid#3, itemname#4, price#5], false
+- Project [itemid#13, count#14]
+- LogicalRDD [userid#12, itemid#13, count#14], false
Physical Plan
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[itemname#4], functions=[sum(1), sum(count#14)], output=[itemname#4, pv#44L, totalcount#45L])
+- Exchange hashpartitioning(itemname#4, 200), ENSURE_REQUIREMENTS, [id=#74]
+- HashAggregate(keys=[itemname#4], functions=[partial_sum(1), partial_sum(count#14)], output=[itemname#4, sum#53L, sum#54L])
+- Project [itemname#4, count#14]
+- SortMergeJoin [itemid#3], [itemid#13], Inner
:- Sort [itemid#3 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(itemid#3, 200), ENSURE_REQUIREMENTS, [id=#66]
: +- Project [itemid#3, itemname#4]
: +- Filter (price#5 > 2.0)
: +- Scan ExistingRDD[itemid#3,itemname#4,price#5]
+- Sort [itemid#13 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(itemid#13, 200), ENSURE_REQUIREMENTS, [id=#67]
+- Project [itemid#13, count#14]
+- Scan ExistingRDD[userid#12,itemid#13,count#14]
AQE(Adaptive Query Execution )
在上面的计划执行过程中有一行,显示了 AdaptiveSparkPlan isFinalPlan=false
默认情况 AQE是关闭的
参考文章: