Spark源码学习(二)-阶段划分和任务执行
Spark应用有这么几个概念: Job, Stage和Task
- Job以行动算子为界, RDD 的 action算子会执行
runJob方法 (SparkContext类). - Stage 以Shuffle依赖为界, 遇到一次Shuffle就会产生新的Stage, 默认会有一个ResultStage;
- Task是Stage子集,以并行度(分区数量)来衡量, 分区数是多少,就有多少个Task.
提交Job
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
上面的关键一行 dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
这是 DAGScheduler类提供的方法.
在这个方法中, 调用了 submitJob 方法
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
在submitJob中, 创建了jobId
val jobId = nextJobId.getAndIncrement()
往一个事件队列中,将这个jobId 和数据,计算逻辑, 分区,扔进去.
// 在DAGScheduler类submitJoby方法
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
Utils.cloneProperties(properties)))
// EventLoop类. post方法
def post(event: E): Unit = {
if (!stopped.get) {
if (eventThread.isAlive) {
eventQueue.put(event)
} else {
onError(new IllegalStateException(s"$name has already been stopped accidentally."))
}
}
}
事件类型
Event处理会用 doOnReceive(event) 完成处理, 在DAGSchedulerEvent类 有这个方法:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerHost = reason match {
case ExecutorProcessLost(_, workerHost, _) => workerHost
case ExecutorDecommission(workerHost) => workerHost
case _ => None
}
dagScheduler.handleExecutorLost(execId, workerHost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case UnschedulableTaskSetAdded(stageId, stageAttemptId) =>
dagScheduler.handleUnschedulableTaskSetAdded(stageId, stageAttemptId)
case UnschedulableTaskSetRemoved(stageId, stageAttemptId) =>
dagScheduler.handleUnschedulableTaskSetRemoved(stageId, stageAttemptId)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
case RegisterMergeStatuses(stage, mergeStatuses) =>
dagScheduler.handleRegisterMergeStatuses(stage, mergeStatuses)
case ShuffleMergeFinalized(stage) =>
dagScheduler.handleShuffleMergeFinalized(stage)
}
第一个模式匹配. 命中了 JobSubmitted 这个case class, 再执行 handleJobSubmitted(jobId ...) 方法,
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
...
```
可见在在这里完成的结果Stage的创建.
# 结果创建 DAGScheduler.createResultStage
```scala
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val (shuffleDeps, resourceProfiles) = getShuffleDependenciesAndResourceProfiles(rdd)
val resourceProfile = mergeResourceProfilesForStage(resourceProfiles)
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd, resourceProfile)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
val parents = getOrCreateParentStages(shuffleDeps, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId,
callSite, resourceProfile.id)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
核心语句 val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite, resourceProfile.id)
结果阶段的构造参数有:
- id, 阶段ID
- rdd, 最后的结果RDD
- func, 途程执行的算子
- partitions, 分区列表
- parents, 上游依赖的阶段 getOrCreateParentStages(shuffleDeps, jobId)
- jobID 提交时的Job ID
- callSite
- resourceProfile.id
上一级阶段的获取方法, getOrCreateParentStages
/**
* Get or create the list of parent stages for the given shuffle dependencies. The new
* Stages will be created with the provided firstJobId.
*/
private def getOrCreateParentStages(shuffleDeps: HashSet[ShuffleDependency[_, _, _]],
firstJobId: Int): List[Stage] = {
shuffleDeps.map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
这个获取上级阶段的方法,又调用了getOrCreateShuffleMapStage
// 获取 可能存在的 ShuffleIdToMapStage, 如果不存在,该方法创建一个Shuffle Map Stage.
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
// Create stages for all missing ancestor shuffle dependencies.
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// Even though getMissingAncestorShuffleDependencies only returns shuffle dependencies
// that were not already in shuffleIdToMapStage, it's possible that by the time we
// get to a particular dependency in the foreach loop, it's been added to
// shuffleIdToMapStage by the stage creation process for an earlier dependency. See
// SPARK-13902 for more information.
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// Finally, create a stage for the given shuffle dependency.
createShuffleMapStage(shuffleDep, firstJobId)
}
}
可见, 该方法使用了 createShuffleMapStage来创建 Shuffle Map的Stage.
/**
* Creates a ShuffleMapStage that generates the given shuffle dependency's partitions. If a
* previously run stage generated the same shuffle data, this function will copy the output
* locations that are still available from the previous shuffle to avoid unnecessarily
* regenerating data.
*/
def createShuffleMapStage[K, V, C](
shuffleDep: ShuffleDependency[K, V, C], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val (shuffleDeps, resourceProfiles) = getShuffleDependenciesAndResourceProfiles(rdd)
val resourceProfile = mergeResourceProfilesForStage(resourceProfiles)
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd, resourceProfile)
checkBarrierStageWithRDDChainPattern(rdd, rdd.getNumPartitions)
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(shuffleDeps, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker,
resourceProfile.id)
stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo(s"Registering RDD ${rdd.id} (${rdd.getCreationSite}) as input to " +
s"shuffle ${shuffleDep.shuffleId}")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length,
shuffleDep.partitioner.numPartitions)
}
stage
}
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker,
resourceProfile.id)
可见阶段的划分就是取决于Shuffle依赖的数量.
阶段数,就是Shuffle依赖的数量+ 1.
任务切分
阶段划分过后, 查看 submitStage 方法
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage): Unit = {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug(s"submitStage($stage (name=${stage.name};" +
s"jobs=${stage.jobIds.toSeq.sorted.mkString(",")}))")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
val missing = getMissingParentStages(stage).sortBy(_.id) 这一行, 要通过 getMissingParentStages 获取可能存在的上一级阶段id, 如果没有上一级,就直接提交本阶段stage的任务. 如果有上一级,就遍历.
submitMissingTasks 中出现了我们关心的任务 -- tasks.
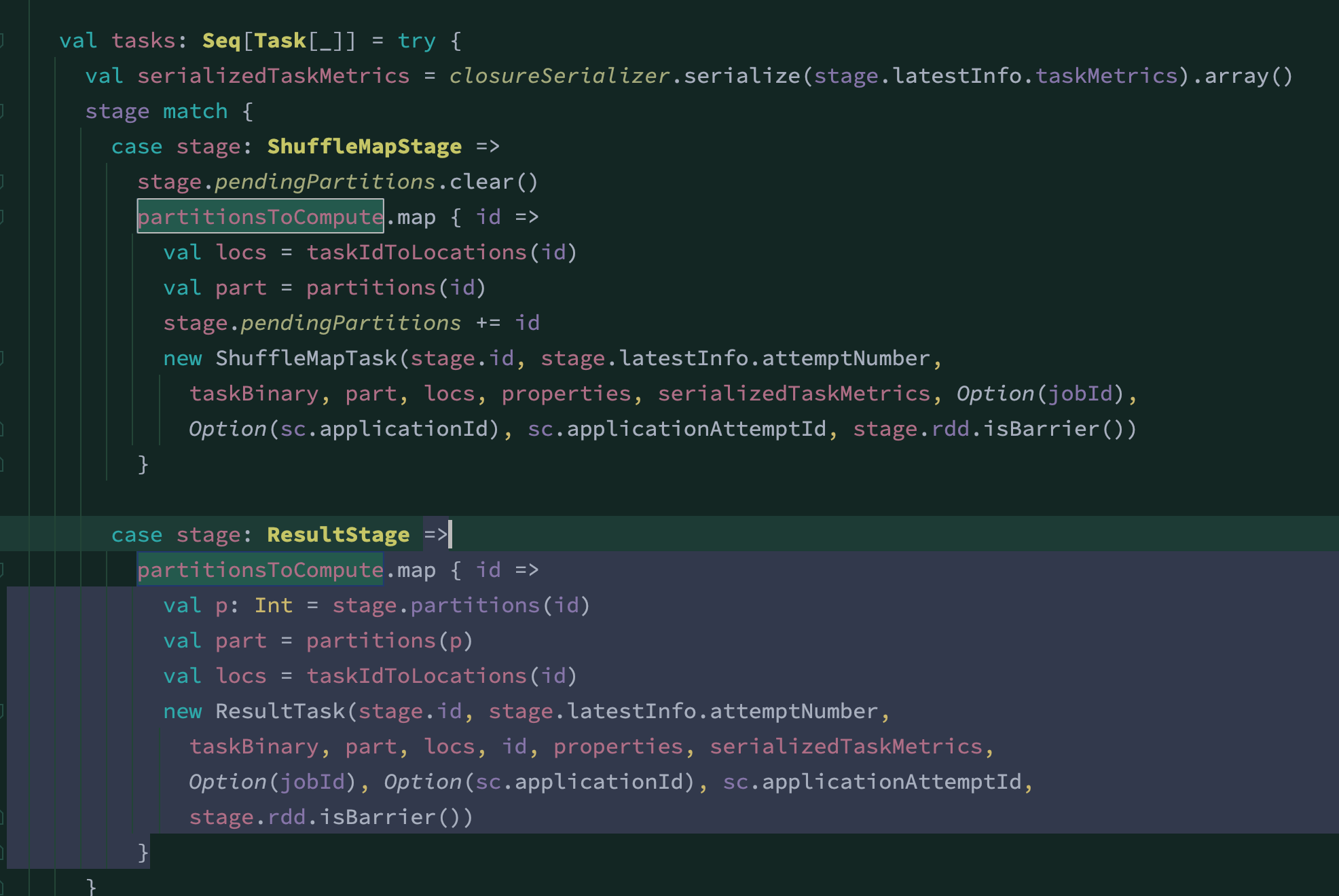
可见, 任务对stage模式区宵只分为两类, ShuffleMapStage和ResultStage.
- 如果是ShuffleMapStage, 创建ShuffleMapTask.
- 如果是ResultStage, 创建ResultTask
任务的划分就是由 partitionsToCompute这个对象指派的.
tasks 创建好之后, 将它们封装在一个TaskSet中, 调用taskScheduer 的submitTasks进行提交
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties,
stage.resourceProfileId))
TaskScheduler 是 Trait, 它的实现是 TaskSchedulerImpl
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false,
clock: Clock = new SystemClock)
extends TaskScheduler
...
提交方法(jjyy)
override def submitTasks(taskSet: TaskSet): Unit = {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks "
+ "resource profile " + taskSet.resourceProfileId)
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// Mark all the existing TaskSetManagers of this stage as zombie, as we are adding a new one.
// This is necessary to handle a corner case. Let's say a stage has 10 partitions and has 2
// TaskSetManagers: TSM1(zombie) and TSM2(active). TSM1 has a running task for partition 10
// and it completes. TSM2 finishes tasks for partition 1-9, and thinks he is still active
// because partition 10 is not completed yet. However, DAGScheduler gets task completion
// events for all the 10 partitions and thinks the stage is finished. If it's a shuffle stage
// and somehow it has missing map outputs, then DAGScheduler will resubmit it and create a
// TSM3 for it. As a stage can't have more than one active task set managers, we must mark
// TSM2 as zombie (it actually is).
stageTaskSets.foreach { case (_, ts) =>
ts.isZombie = true
}
stageTaskSets(taskSet.stageAttemptId) = manager
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run(): Unit = {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
核心语句, val manager = createTaskSetManager(taskSet, maxTaskFailures)
创建了一个TaskSetManager, 即将TaskSet作为参数,又打了一层包.
任务调度
schedulableBuilder, 任务调度器, 在初始化时会根据模式进行初始化.
def initialize(backend: SchedulerBackend): Unit = {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, sc)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
Spark默认的调度器是FIFOSchedulableBuilder.
关注 rootPool 变量, 所谓任务调度就是将若干个任务放在一个池子里,然后以某种策略取出来执行的过程.
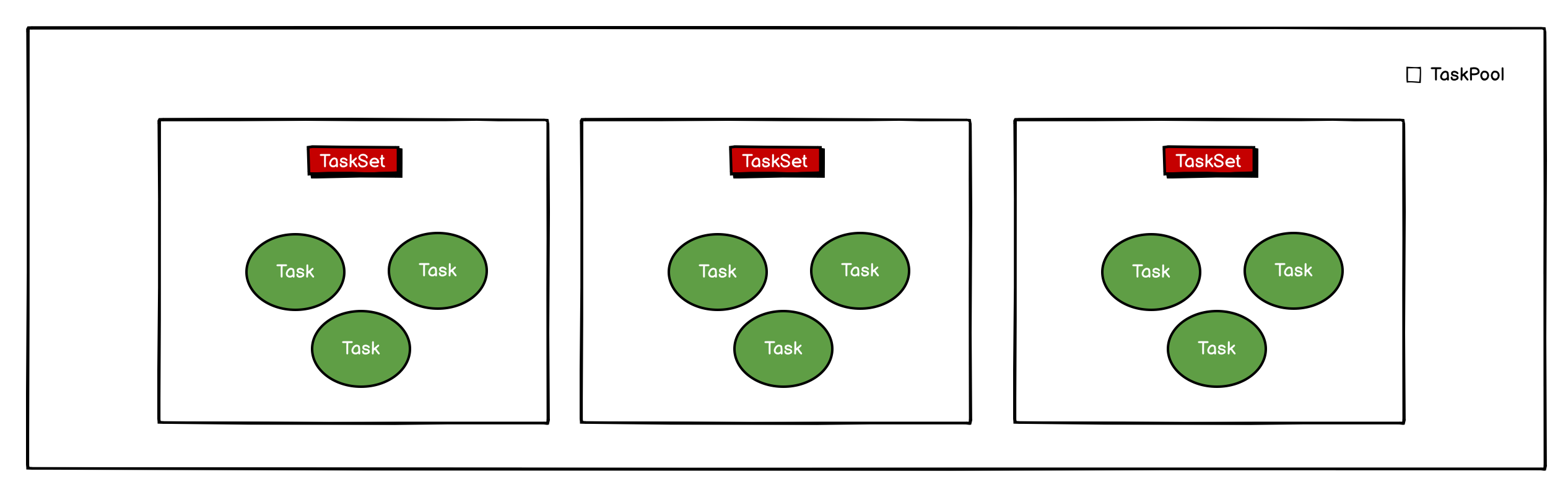
任务池的对面, 是谁来取任务调用呢?
SchedulerBackend
SchedulerBackend 是个特质, 实现 class CoarseGrainedSchedulerBackend(scheduler: TaskSchedulerImpl, val rpcEnv: RpcEnv), 我管它叫调度后端录杂粮版.
调用receiverOffers 从TaskPool取任务. 最终执行, 关注方法 ~makeOffers
// Make fake resource offers on all executors
private def makeOffers(): Unit = {
// Make sure no executor is killed while some task is launching on it
val taskDescs = withLock {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(isExecutorActive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores,
Some(executorData.executorAddress.hostPort),
executorData.resourcesInfo.map { case (rName, rInfo) =>
(rName, rInfo.availableAddrs.toBuffer)
}, executorData.resourceProfileId)
}.toIndexedSeq
scheduler.resourceOffers(workOffers, true)
}
if (taskDescs.nonEmpty) {
launchTasks(taskDescs)
}
调度算法 SchedulingAlgorithm
SchedulingAlgorithm是特质, 实现也有两种, FIFO和Fair.
Task 分发的策略
Task是计算逻辑, 面对三个Executor, Driver将Task发给谁呢?
移动数据不如移动计算.
在调度执行时, Spark调度总是尽量让每个task以最高的LocalityLevel来尝试获取RDD.
这也是 RDD中 getPreferredLocation 方法的对应:
计算和数据的位置,有不同的"level",这个称为本地化级别;
- 如果是同在一个进程当中, 称为进程本地化, 效率是最高的; (PROCESS_LOCAL)
- 节点本地化, 较上次之; (NODE_LOCAL)
- rack本地化, 较上次之; (RACK_LOCAL)
- else, 最次. ANY 性能最差
- NO_PREF
启动任务
杂粮调度器后端 :
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]): Unit = {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
s"${RPC_MESSAGE_MAX_SIZE.key} (%d bytes). Consider increasing " +
s"${RPC_MESSAGE_MAX_SIZE.key} or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
// Do resources allocation here. The allocated resources will get released after the task
// finishes.
val rpId = executorData.resourceProfileId
val prof = scheduler.sc.resourceProfileManager.resourceProfileFromId(rpId)
val taskCpus = ResourceProfile.getTaskCpusOrDefaultForProfile(prof, conf)
executorData.freeCores -= taskCpus
task.resources.foreach { case (rName, rInfo) =>
assert(executorData.resourcesInfo.contains(rName))
executorData.resourcesInfo(rName).acquire(rInfo.addresses)
}
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
关键代码, executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
从任务池中获取任务 (序列化后) 发给 executor 执行.
DAGScheudler的注释
- The high-level scheduling layer that implements stage-oriented scheduling. It computes a DAG of stages for each job, keeps track of which RDDs and stage outputs are materialized, and finds a minimal schedule to run the job.
- It then submits stages as TaskSets to an underlying TaskScheduler implementation that runs them on the cluster. A TaskSet contains fully independent tasks that can run right away based on the data that's already on the cluster (e.g. map output
files from previous stages), though it may fail if this data becomes unavailable. - It then submits stages as TaskSets to an underlying TaskScheduler implementation that runs them on the cluster. A TaskSet contains fully independent tasks that can run right away based on the data that's already on the cluster (e.g. map output files from previous stages), though it may fail if this data becomes unavailable.