Spark源码学习(四)-内存管理
查看源码的入口类, Spark的 SparkEnv:
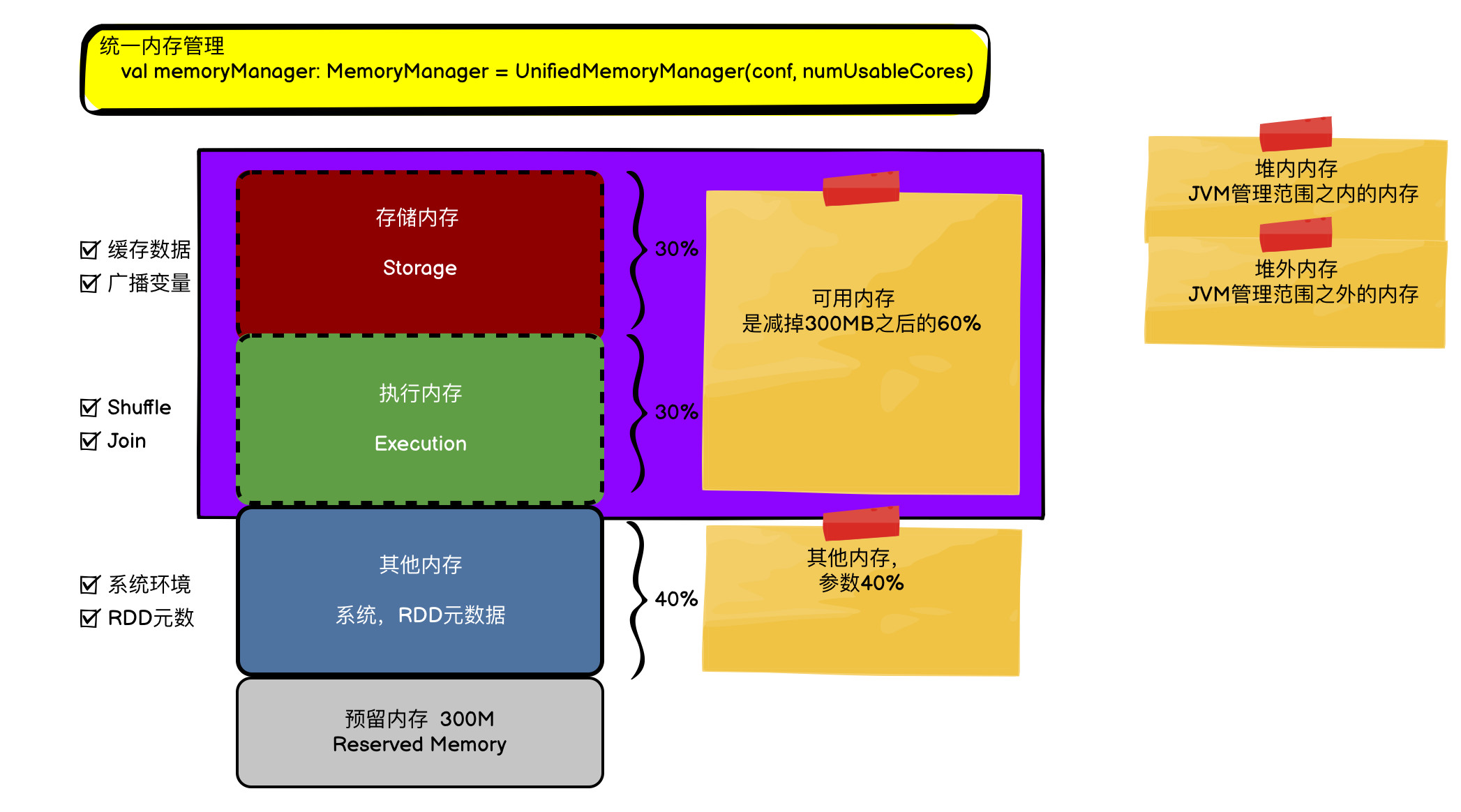
val memoryManager: MemoryManager = UnifiedMemoryManager(conf, numUsableCores)
声明语句中val memoryManager: MemoryManager MemoryManager是抽象类, 在Spark2.x(还是3.0?) 之后,只保留了唯一的实现继承类 - UnifiedMemoryManager(统一内存管理者), 去除了之前的静态内存管理者。
源码中对 MemoryManager类的注释:
MemoryManager 是控制execution内存和storage内存的边界,以及借用内存的机制。
Execution与Storage共享的区域是通过 spark.memory.fraction 这个参数(默认为0.6)控制的,
它是总堆空间 与300MB之差的一部分组成。
此空间的边界位置(软边界)由spark.memory.storageFraction进一步确定,默认是0.5。
这意味着storage区域的大小默认大小是0.6*0.5 = 0.3.
存储storage区域可以借用尽可能多的执行内存,直到执行区有需求时再讨要回来。
(发生时机,缓存的block将从内存中被淘汰,直到释放出足够内存供执行区满足需求) 。
相应地,执行区内存也能借用尽可能多的存储区,以完成任务。但是,执行区内存*永远* 不会被存储区淘汰。
好处是存储内存和执行内存可以互相占用。
UnifiedMemoryManager
abstract class MemoryManager(
conf: SparkConf,
numCores: Int,
onHeapStorageMemory: Long,
onHeapExecutionMemory: Long)
private[spark] class UnifiedMemoryManager(
conf: SparkConf,
val maxHeapMemory: Long,
onHeapStorageRegionSize: Long,
numCores: Int)
MemoryManager构造参数, 核数量, 存储区内存大小, 执行区内存大小。
UnifiedMemoryManagerr 主要构造参数: 占用的核数量, 执行最大内存,堆内存储区大小。
主要方法
- getMaxMemory, 获得执行内存+存储内存, 返回数字表示多少个bytes 并指定了 minSystemMemory, 要求 Exeucotr分配内存的最小值必须要大于 保留300MB的1.5倍.
memoryFraction 可用内存的比例,默认大小是0.6 (即 存储+执行内存的比例)
- apply方法 将获取的0.6比例 再分配执行区和存储区, 默认比例0.5, 即存储和执行区各占0.3
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
onHeapStorageRegionSize =
(maxMemory * conf.get(config.MEMORY_STORAGE_FRACTION)).toLong,
numCores = numCores)
}
四三三分配
默认1GB的Executor内存,先指派给Reserved 300MB,然后余下的724MB
40%分配给User 区域 289.6MB
60%分配 给执行+存储区 即为434.4MB, 存储和执行分别初始分配217 MB
onHeap, offHeap
JVM管理的是堆内内存(onHeap-memory), 堆内内存在java中使用GC只能通知释放,并不能真正控制。
使用offHeap 堆外内存,能实现灵活的内存控制(相对来说不安全,有操作风险)。
public enum MemoryMode {
ON_HEAP,
OFF_HEAP
}
第一次看到的Spark中的枚举类。
动态占用机制
- 如果存储和执行区内存都满了,那么就得执行spill-to-disk。
- 如果Storage不足,而Execution有空余,Storage可以占用部分Execution;
- 如果Execution不足,而Storage有空余,Execution可以占用部分Storage;
2和3的区别是—— Execution借了的内存涌被evict(淘汰), Storage借了的内存可以被evict(淘汰)
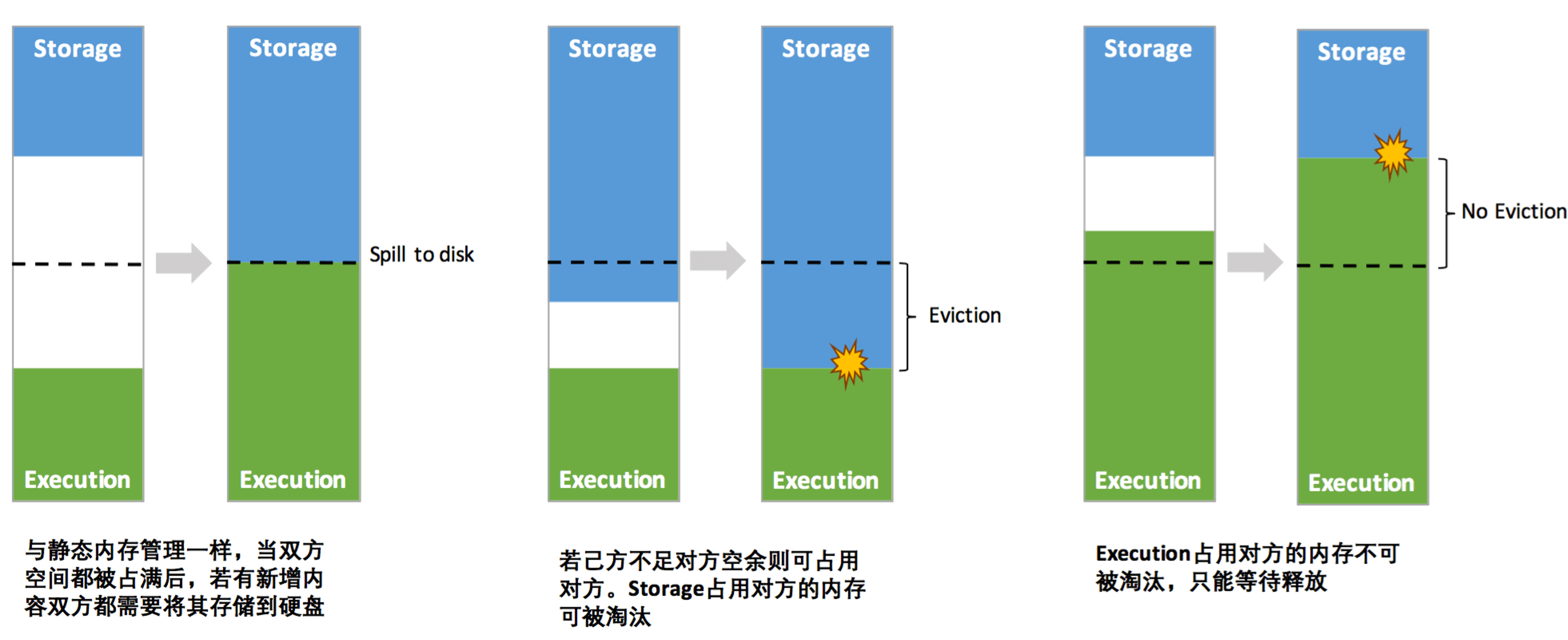
内存对象是否要执行Evict也取决于对象的存储级别(StorageLevel)

为什么Execution借的内存可以不还
存储内存如果不够了,再从硬盘读,只影响性能,不影响任务的运转。
执行内存如果不够了,数据就没了。
相关参数设置
-
TEST_MEMORY(spark.testing.memory)
- .createWithDefault(Runtime.getRuntime.maxMemory)
-
TEST_RESERVED_MEMORY (spark.testing.reservedMemory)
-
RESERVED_SYSTEM_MEMORY_BYTES 保留区内存大小, 默认300MB, 用于非存储、非执行使用
-
EXECUTOR_MEMORY(spark.executor.memory) 默认1个G, Executor进程占用的内存总大小