Spark Tuning
文章主题, Spark调优。
Spark 任务要避免成为集群的运转负担,包括不合理的占用CPU、带宽和内存资源。
官方的Tuning文档
Tuning Spark 文档介绍了调优的三个思路:
- Data Serialization 数据序列化
- Memory Tuning 内存调优
- 其它考量
数据序列化
分布计算中数据的序列化非常重要.
- Java Serialzation, 自定义类需要继承
java.io.Serializable要有public的构造方法, 所有属性是public, POJO 类. - Kryo Serialization, 支持的范围比 Java Serialization 少, 但能支持的场景性能要高.
设置时机是在SparkConf环节: conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
在Spark2.0.0 之后, 使用Kryo对简单数据类型进行序列化。
内存优化
一直以为,笔者是很少关注内存的优化细节,一般用的都是别人提供的参考参数列表,对一半以上参数的调参方式也不太了解。 当出现调优的工作需求时,往往就要被动学习了。
内存使用的优化要考虑哪些问题?
你的对象占用多大的内存空间, 能否将dataset全部加载到内存中?
访问这些对象的开销是什么
GC(垃圾回收)的消耗
Java对象的特点, 每个Java对象都拥有自己专属的`对象头信息 , 大约16个byte, 包括 mark world (锁, hashcode), klass pointer 指向自己的类指针, 对于特别小的object, 这个对象头可能比Instance data的尺寸还大.
Java String有额外的40bytes大小,要存储 String作为一个char数组的额外信息(长度,编码等). 例子,一个10个character的字符串,实际占用的空间可能至少要60bytes.
一般集合对象(Hashmap, LinkedList等),会对存储元素进行装饰(比如 Map.Entry), 每个对象除了对象头信息,还有指向下一个对象的指针.
存储原子类型的集合,会存储它们的装箱类(int - > java.lang.Integer)
Spark内存管理
Spark将内存划分为两类, execution执行区 和 storage存储区, 执行区内存用来Shuffle, Join, Sort和Aggregation, 存储区用于缓存\ 集群间的对象传递.
在Spark1.6之后使用统一内存管理模型,废弃了老版的静态内存管理机制, 使用统一内存管理, 即 执行+存储共用一片区域, 称为 "M" Spark官方文档-Tuning Spark
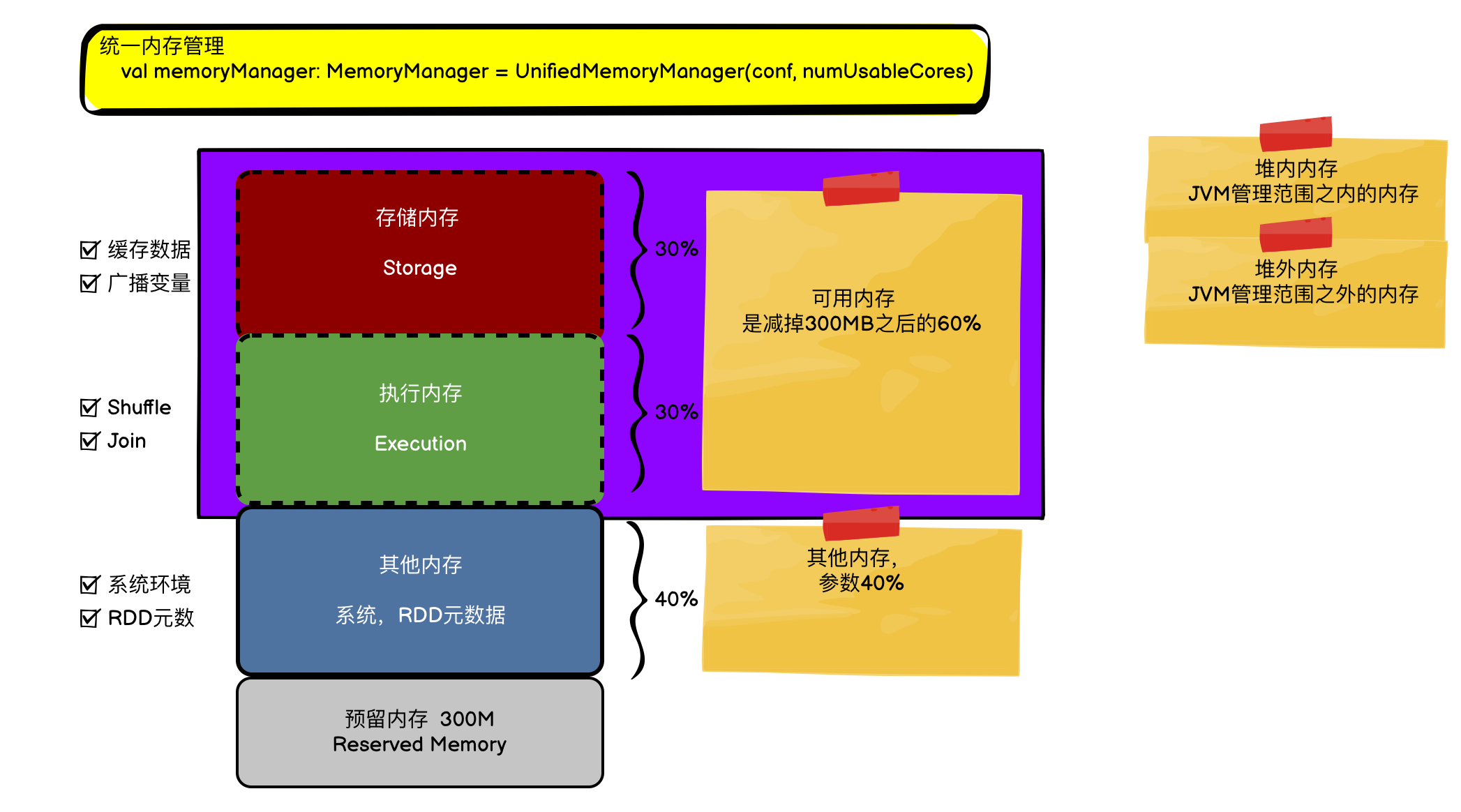
保留内存占用300MB, 余下的空间 :
- Execution Memory + StorageMory 是干活和存储内存, 共占用空间是
spark.memory.fraction默认值0.6。- Storage 的占比由 另一个参数
spark.memory.storageFraction控制 默认值0.5
- Storage 的占比由 另一个参数
- User Memory , 占用空间是 【1 - spark.memory.fraction】
所谓的内存管理主要是关注的上面的 Execution内存和Storage内存。
Execution内存正是用于处理shuffle,join,sorts和aggregation过程。
Storage内存是用于数据缓存。
二者是能互相占用的,这也是统一内存管理的统一(Unified)所指:
- M: execution + storage 的region, 即上面的 0.6 控制的空间。
- R: execution 当storage memo 不够时会匀一部分给到Storage, 这个阈值由上面的storageFraction 控制。 即R表示 Storage最少占用的比例。
设置建议, spark.memory.fraction 应与JVM堆空间的老年代保持一致。
内存优化的思路
-
data structures
- Design阶段,避免 嵌套型数据结构, 尽可能使用 numeric IDs 替换字符串key
- JVM参数, -XX:+UseCompressedOops
-
Serialized RDD存储 RDD StorageLevel
-
GC调优
- -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps to the Java options.
- HeapSize调整
- GC collector设置, 如
- G1, -XX:+UseG1GC, -XX:G1HeapRegionSize
The Young generation is further divided into three regions [Eden, Survivor1, Survivor2].
YARN的参数优化
YARN控制集群整体的计算资源,对于Spark任务来说,它对集群的资源依赖就是«核数, 内存»。 有下面3对6个参数:
yarn.nodemanager.resource.memory-mb 为每个node分配的容器内存,上限是该节点的总内存
yarn.scheduler.maximum-allocation-mb 不同scheduer处理时动态处理后的最小最大要求
yarn.scheduler.minimum-allocation-mb
yarn.nodemanager.resource.cpu-vcores 单个节点获得的核数
yarn.scheduler.maximum-allocation-vcores
yarn.scheduler.minimum-allocation-vcores
其它优化思路
任务的并行化
关注参数, spark.default.parallelism
官方推荐, 每个CPU core 执行并行执行2-3个任务。
Reduce过程的内存使用
多数情况下,我们遇到的OOM都是发生在Reduce阶段。
典型例子, 在使用 groupByKey 时,有大批量的数据在Shuffle阶段, 需要为每个task准备一个大的HashTable, 以执行数据的分组装配,通常这个HashTable会占用较多的空间,OOM也多发现在与这个大数据结构中。
大空间的广播变量 与 数据本地化
Spark SQL Tuning
https://spark.apache.org/docs/latest/sql-performance-tuning.html